
论文标题:Relaxed Transformer Decoders for Direct Action Proposal Generation 论文链接:https://arxiv.org/abs/2102.01894 代码链接:https://github.com/MCG-NJU/RTD-Action 作者单位:南京大学(王利民, 武港山等) 本文对DETR进行了三项重要的改进,将Transformer首次用于时序动作提案生成任务,表现SOTA!性能优于RapNet、BMN和G-TAD等,代码即将开源!
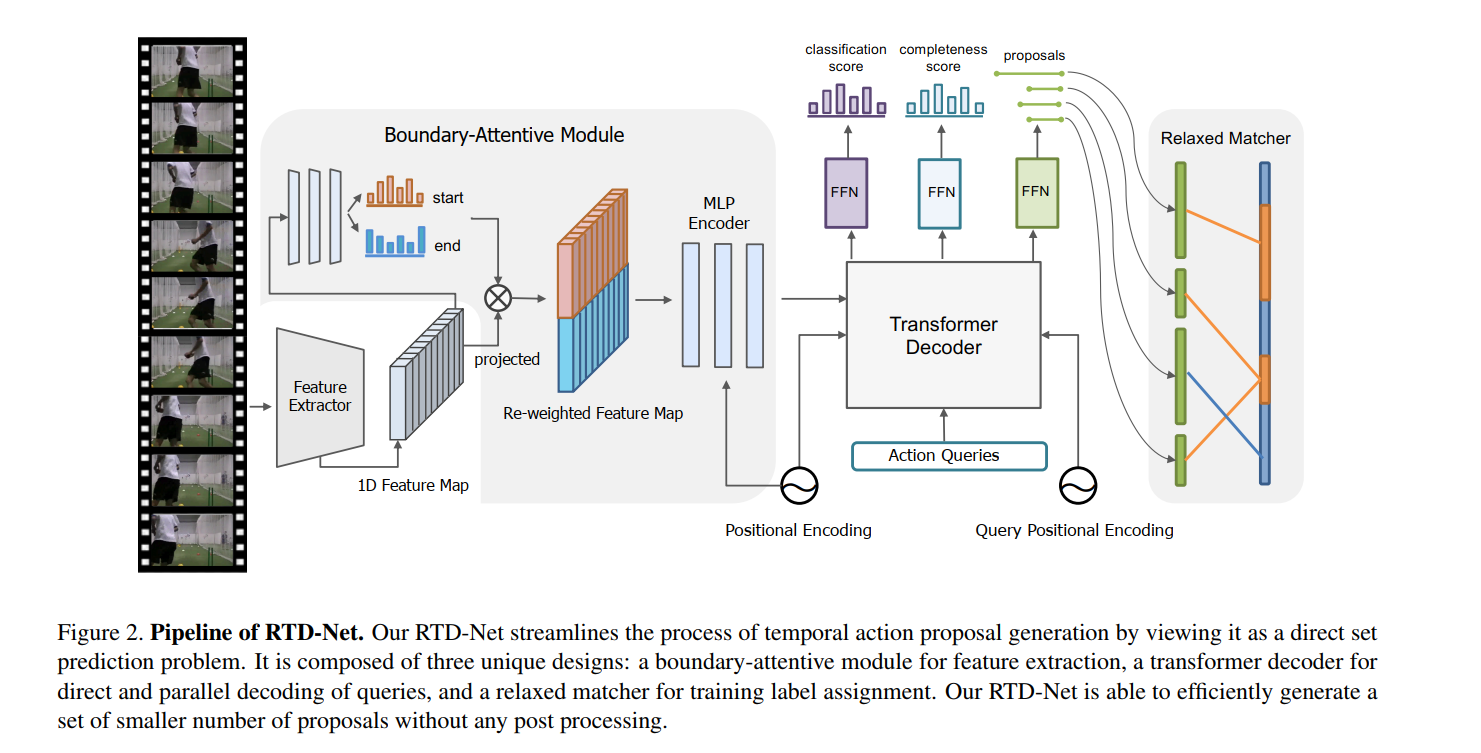
时序动作提案生成是视频理解中一项重要且具有挑战性的任务,其目的是检测包含感兴趣的动作实例的所有时间片段。现有的提案生成方法通常基于预定义的anchor口或启发式自下而上的边界匹配策略。本文通过重新提出类似“Transformer”的架构,提出了一种用于直接动作提案生成的简单且端到端的可学习框架(RTD-Net)。为了解决时间和空间之间的本质视觉差异,我们对原始的transformer检测框架(DETR)进行了三项重要的改进。首先,为了处理视频中的先验延迟,我们用边界注意力模块替换了原始的Transformer编码器,以更好地捕获时间信息。其次,由于时间边界不明确且注释相对稀疏,我们提出了一种宽松的匹配损失,以减轻对每个地面真实情况进行单一分配的严格标准。最后,我们设计了一个三分支机构,通过明确预测其完整性来进一步改善建议置信度估计。在THUMOS14和ActivityNet-1.3基准上进行的大量实验证明了RTD-Net在temporal action proposal generation and temporal action detection任务上的有效性。此外,由于其设计简单,我们的RTD-Net比以前的proposal generation 方法更有效,并且没有非极大值抑制后处理。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢