
题目:Pre-training via Paraphrasing
作者:Mike Lewis, Marjan Ghazvininejad, Gargi Ghosh, Armen Aghajanyan, Sida Wang, Luke Zettlemoyer,来自 Facebook AI
发表情况:NIPS 2020
推荐理由:
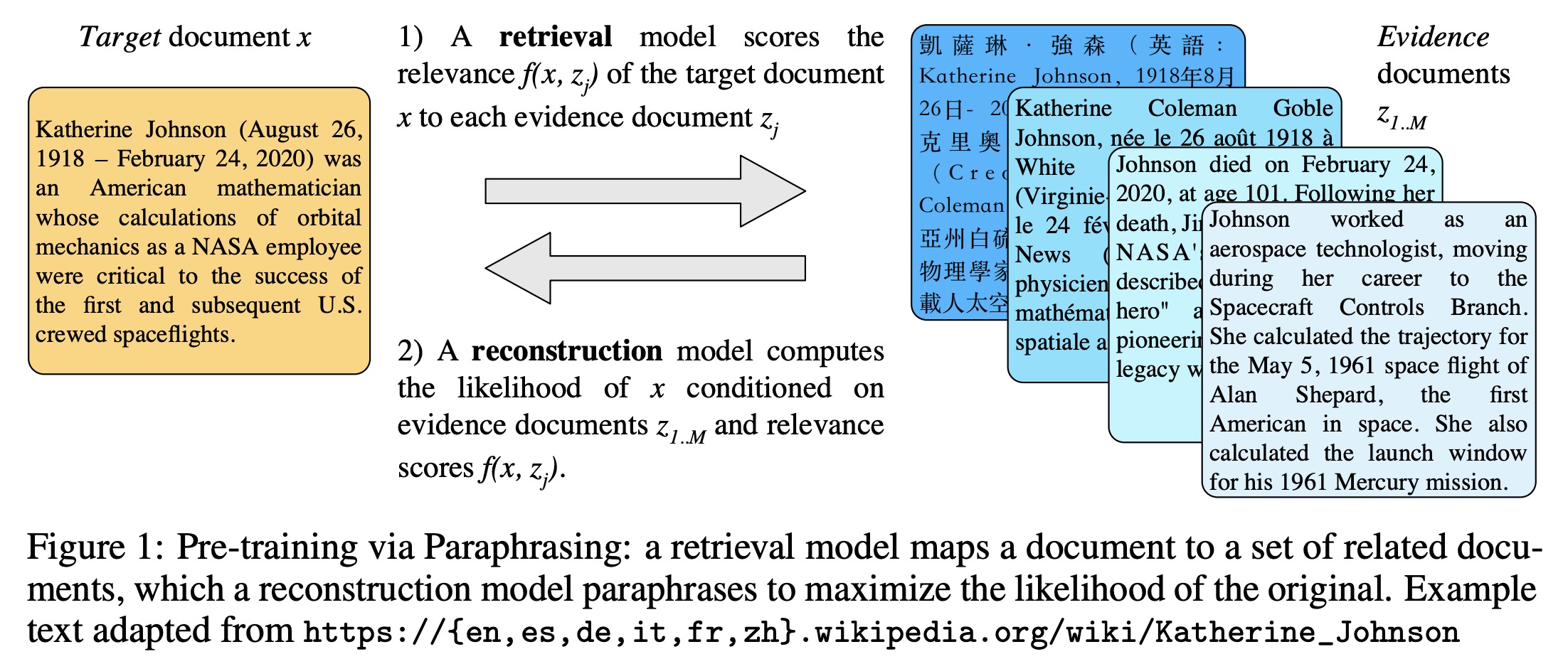
本文提出了MARGE:一个新的序列到序列预训练模型,在无监督多语言多文档复述目标下进行学习。MARGE的提出,为主流的掩码语言模型(MLM)提供一种新的范式。在掩码语言模型范式中,往往通过检索一组相关的文本(在许多语言中)来进行自监督文本重构,对它们进行条件设置,来最大限度地提高生成原始文本的可能性。本文的工作展示了联合学习做检索和重建是可能的(只需要给出一个随机初始化)。在没有额外的任务预训练情况下,MARGE在文档翻译方面的BLEU分数高达35.8。进一步实验表明,微调在许多语言的一系列辨别性和生成性任务上有很强的表现,使MARGE成为迄今为止最普遍适用的预训练方法。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢