
论文:Unified Vision-Language Pre-Training for Image Captioning and VQA
作者:Luowei Zhou, Hamid Palangi, Lei Zhang, Houdong Hu, Jason J. Corso, Jianfeng Gao,来自微软
发表情况:AAAI 2020
代码和预训练的模型:https://github.com/LuoweiZhou/VLP
推荐理由:
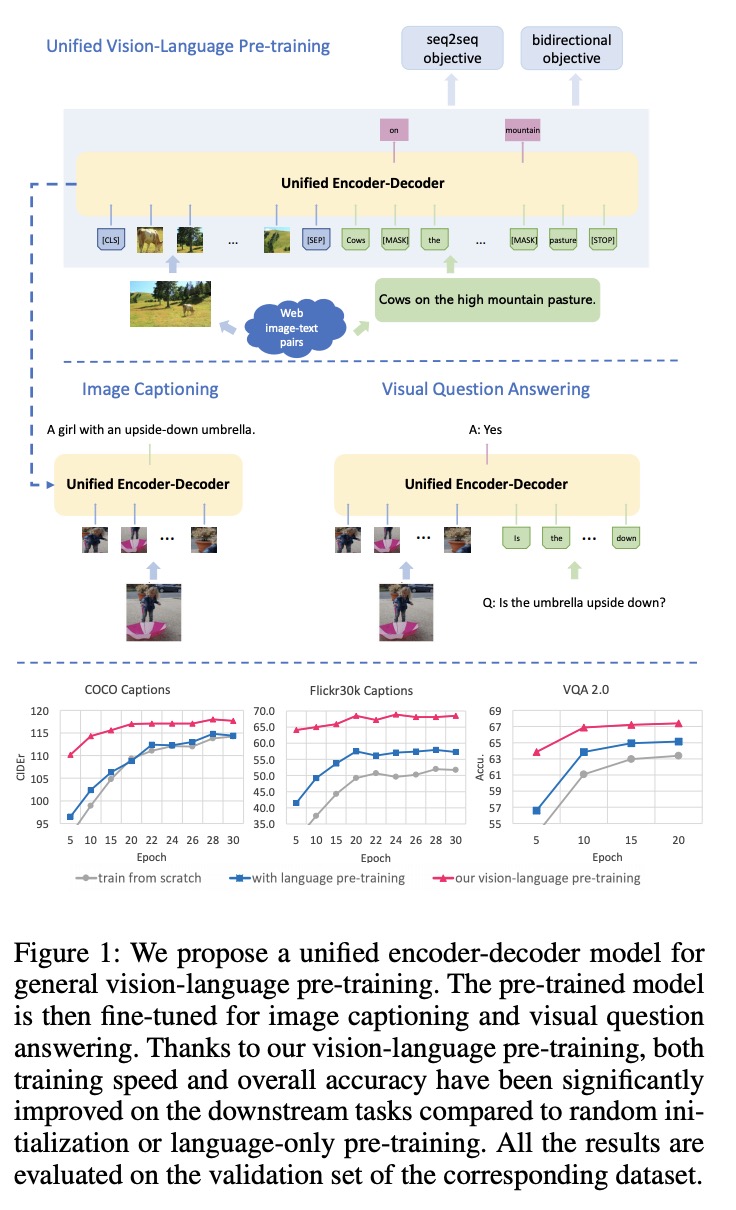
本文提出了一种统一的视觉语言预训练模型(VLP)。模型可以整合视觉语言的生成(如图像字幕)或理解(如视觉问答)任务。不同于许多现有方法的编码器和解码器使用单独的模型实现,VLP模型使用一个共享的多层transformer网络编码和解码。VLP模型在大量的图像-文本对上预训练,使用了两个无监督学习目标:双向和(seq2seq)掩码视觉-语言预测(bidirectional and sequence-to-sequence (seq2seq) masked vision-language prediction)。这两个任务的区别仅在于预测条件所处的上下文环境是不同的。然后通过为共享的transformer提供特定的自注意掩码来控制。VLP是第一个视觉-语言预训练模型,它在视觉语言生成和理解任务上都取得了最先进的结果,在三个具有挑战性的基准数据集:COCO字幕、Flickr30k字幕和VQA 2.0上均取得了不错的性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢