
题目:Adversarial Robustness: From Self-Supervised Pre-Training to Fine-Tuning 作者:Tianlong Chen, Sijia Liu, Shiyu Chang, Yu Cheng, Lisa Amini, Zhangyang Wang,来自Texas A&M University、微软、MIT-IBM Watson AI Lab 发表情况:CVPR 2020 代码:https://github.com/VITA-Group/Adv-SS-Pretraining 推荐理由: 自监督的预训练模型普遍用于更快或更好地微调下游任务。然而,如何从预训练中获得鲁棒的性能还有待研究。本文将对抗训练引入自监督,首次提供了通用鲁棒的预训练模型。
这些鲁棒的预训练模型有两个优点: i) 提高最终模型的鲁棒性; ii) 如果进行对抗性微调的话,能够节省计算成本。
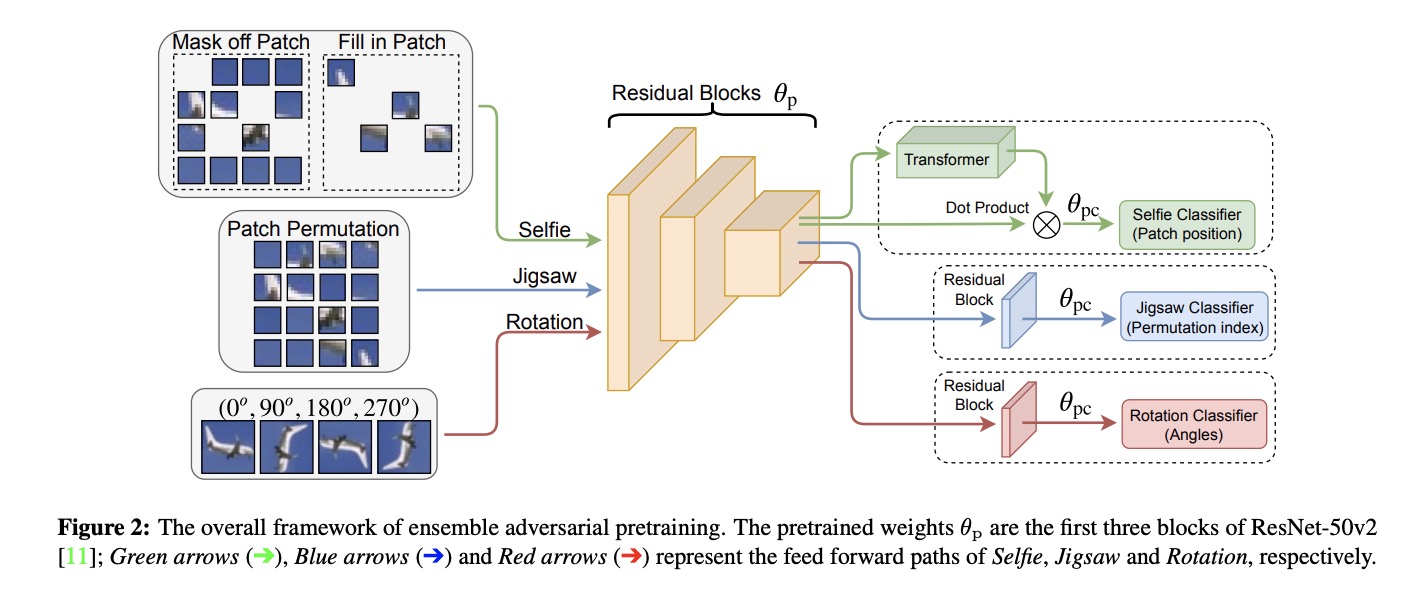
大量实验证明,与传统的端到端对抗训练基线相比,所提出的框架实现了较大的性能边际收益(例如,在CIFAR-10数据集上,鲁棒精度3.83%,标准精度1.3%)。此外,本项目还发现不同的自监督预训练模型具有不同的对抗脆弱性。如果使用集成几个预训练任务,可以增强模型的鲁棒性。本项目的集成策略在原有的精度提升上进一步提高了3.59%,同时在CIFAR-10上保持了不过的标准精度。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢