
论文标题:Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision 论文链接:https://arxiv.org/abs/2102.05918 作者单位:Google Research(Quoc V. Le等人) 1024块TPU在燃烧!在图像分类、跨模态图像-文本匹配/检索任务上表现SOTA!如在ImageNet上高达88.64% top-1准确率!性能优于CLIP等。
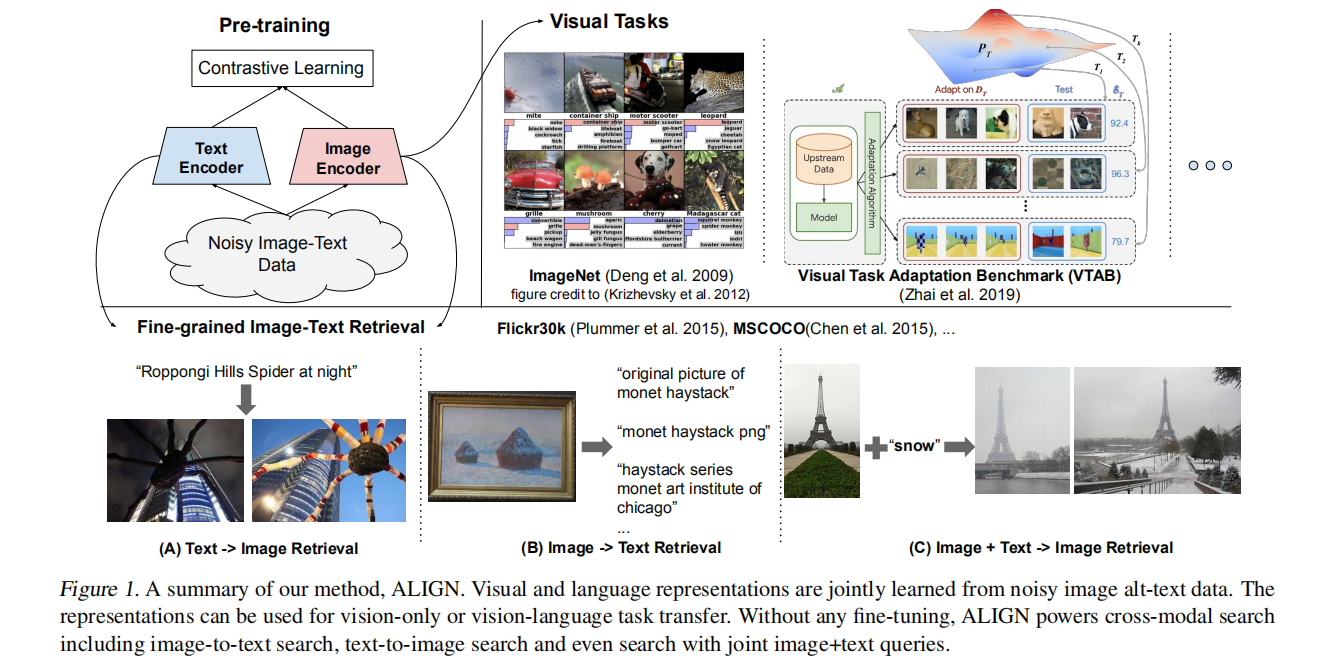
预训练的表示形式对于许多NLP和感知任务变得至关重要。尽管NLP中的表示学习已过渡到在没有人工注释的情况下对原始文本进行训练,但视觉和视觉-语言表示仍然严重依赖于精选的昂贵或需要专家知识的训练数据集。对于视觉应用,通常使用具有显式类标签的数据集(例如ImageNet或OpenImages)来学习表示。对于视觉-语言,流行的数据集(如Conceptual Captions,MSCOCO或CLIP)都涉及非平凡的数据收集(和清理)过程。这种昂贵的策划过程限制了数据集的大小,因此阻碍了训练模型的扩展。在本文中,我们利用了超过十亿个image alt-text pairs的嘈杂数据集,而无需在Conceptual Captions数据集中进行昂贵的过滤或后处理步骤即可获得。一个简单的双编码器体系结构学习使用对比损失来对齐图像和文本对的视觉和语言表示。我们证明,即使采用这种简单的学习方案,我们的语料库的规模也可以弥补它的noisy,并能提供最先进的表示方法。当迁移到诸如ImageNet和VTAB之类的分类任务时,我们的视觉表示可实现出色的性能。即使与更复杂的交叉注意力模型相比,对齐的视觉和语言表示也为Flickr30K和MSCOCO基准设置了最新的最新结果。这些表示还可以使用复杂的文本和文本+图像查询来进行跨模态搜索。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢