
强化学习(RL)在游戏界的成功已经在 AI 界产生了轰动。当大家还在认为强化学习只能用于游戏环境时,强化学习的落地技术已成Google、DeepMind等科技巨头争相研究的焦点。巨头们趋之若鹜的背后,是智能决策背后隐藏着的巨大商业价值。
如何让智能决策的落地?离线强化学习(Offline RL)也许是实现目标的最佳路径,因为这使得强化学习可以不依赖于模拟环境,直接从收集的大量历史数据中学习策略。为了推动强化学习技术落地,许多机构提出了各种各样的基准数据集、基准任务以模拟离线强化学习面临的挑战,然而近期南京大学、南栖仙策、上海交通大学等单位的研究者发现,现有离线强化学习的测试基准与实际应用有很大的差异,难以支撑强化学习的落地。
我们知道,离线强化学习旨在从已收集到的数据中学习最优的策略,在训练过程中其不需要与环境进行额外的交互。离线强化学习试图减少在环境中的危险行为,从而极大地拓宽强化学习的应用范围。
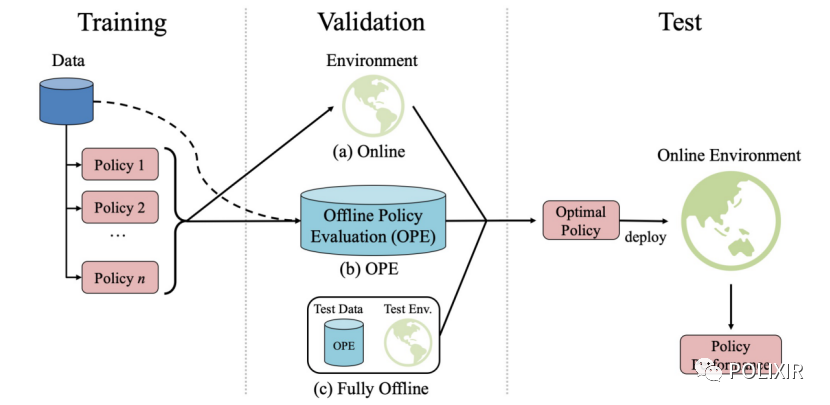
然而,研究者们发现目前的离线强化学习基准包含由高度探索性策略收集的大型数据集,并且一个训练的策略会直接在环境中评估。在现实世界中,为了确保系统安全,往往会禁止运行具有高度探索性的策略。这导致强化学习研究者们产生了一个普遍性的问题:数据通常非常有限,在部署之前如何对训练好的策略进行充分验证?
据了解,为解决以上问题,近期一家专注于智能决策的人工智能新锐公司,脱胎于南京大学人工智能学院的南栖仙策联合南京大学、上海交通大学,提出了一套接近真实世界的基准——NeoRL。
NeoRL包含来自不同领域、大小可控的数据集,以及用来做策略验证的额外测试数据集。我们选择一些任务构建具有接近真实世界应用属性的数据集。与之前的工作相比,我们提出的任务考虑了上述现实差距,并在此基础上,模拟现实世界中可能遇到的各种复杂情况,构建不同性质的离线数据集。
NeoRL具有以下特点:
- 接近现实的环境和奖励函数
- 多级策略和灵活的数据划分
- 统一的API接口和丰富的基准算法对比
南栖仙策在NeoRL上评估现有的离线强化学习算法。在实验中,策略的表现也应该与确定性版本的行为策略(the deterministic version of behavior policy)进行比较,而不仅仅是数据集奖励。因为真实系统应用中通常有一个确定性策略,而为了增加数据多样性或者进行轻度探索,数据集通常是对该策略输出的动作加入扰动来收集的,这会降低该策略的表现。此外,在策略部署前,需要对策略进行充分的性能评估,而不是直接放到线上环境运行得出结果,这在真实场景中是不可接受的。
实验结果表明,在许多数据集上,离线强化学习算法的表现和这个确定性策略表现类似,并且离线策略评估(offline policy evaluation)对模型选择几乎没有帮助。南栖仙策希望这项工作能对强化学习在实际系统中的研究和部署有所帮助。
NeoRL目前向开发者及强化学习爱好者免费提供,包含:文章、测试基准代码库、数据集下载、离线强化学习算法库。以及安装与使用教程。
详情可以戳链接:http://polixir.ai/research/neorl](http://polixir.ai/research/neorl)
来源:南栖仙策
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢