
作者:hellobill | 比尔的新世界
在之前的文章中,作者介绍了FTRL、FM、Wide&Deep、DeepFM等经典排序算法,这也是工业实践当中常见的模型演进路线,作者本人就亲历了从FTRL到FTRL+连续值DNN,再到大规模离散DNN,然后是Wide&Deep的迭代过程。期间还尝试了各种其它的模型结构,比如DeepFM、CIN、DIN等,线下取得了一定的收益但是却都没有上线,下面就尝试跟大家讨论一下为什么一些鼎鼎大名的模型在我们的业务场景下却不work。
DNN模型的优化方向主要有两条线,一个是网络结构的优化,另一个是embedding特征交叉方式的优化。借用腾讯技术工程出品的推荐系统 embedding 技术实践总结[2] 一文当中的一张图,该图简洁明了的列出了这两条优化路线下都发展出了哪些模型。
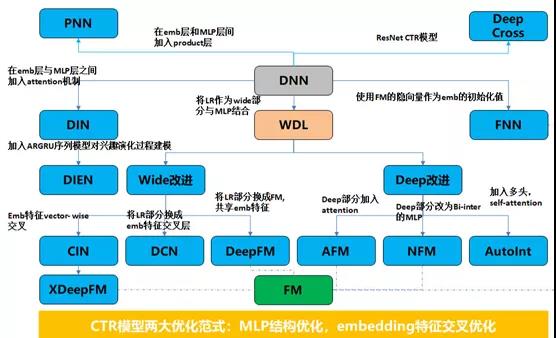
以DeepFM模型为例,FM部分对所有输入特征的embedding做了两两点积,如果我们的特征粒度很粗,且没有多少交叉特征,可能效果会好很多,但是我们从FTRL模型演进过来,特征工程工作已经做的很细了,哪些交叉特征有用哪些没用,我们已经做过筛选和验证,留给FM发挥的空间已经不多了,何况FM的无脑交叉会在已有交叉的基础上再交叉,在完全没必要的地方交叉,信息的冗余可想而知。
其实模型的工作基本可由特征工程来替代,但是特征工程的作用模型不一定能做的很好。特征工程虽然看起来是个脏活累活,但是它扎实可靠,复杂模型看起来高大上,但是其实虚的很。
以DIN为例,目的是希望在用户的行为序列当中区分出哪些行为更重要,比如越近的行为可能越重要,频率越高的行为可能越重要,这种重要性可能可以通过用户行为特征与Item特征的交互学习得到,但是既然我们已经想到了需要哪些信息,那自然可以将这些信息变成特征输入到网络中去。比如将用户的行为按时间做更细粒度的划分,是不是就可以刻画用户行为时间与用户兴趣的关系呢,将用户对不同Item行为的频率作为特征,是不是就可以刻画用户行为频率与用户兴趣的关系呢。增加更为丰富的信息,这是开源,针对既有特征使用更为巧妙的模型,这是节流,中国人讲究既开源又节流,没毛病吧,所以一般算法部门会有特征组和模型组两拨人员同时进行算法的优化。
参考资料
[1] https://mp.weixin.qq.com/s/GnVExcF1fE6YdqVep129aw [2] https://zhuanlan.zhihu.com/p/143763320
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢