
论文标题:OmniDet: Surround View Cameras based Multi-task Visual Perception Network for Autonomous Driving 论文链接:https://arxiv.org/abs/2102.07448 作者单位:法雷奥Valeo(德国/爱尔兰/法国等) 本文实现了首个实时用于环绕鱼眼镜头感知的六大任务模型(深度估计,视觉里程计,语义分割,运动分割,目标检测和镜头污染检测),联合训练比单独执行效果更好!
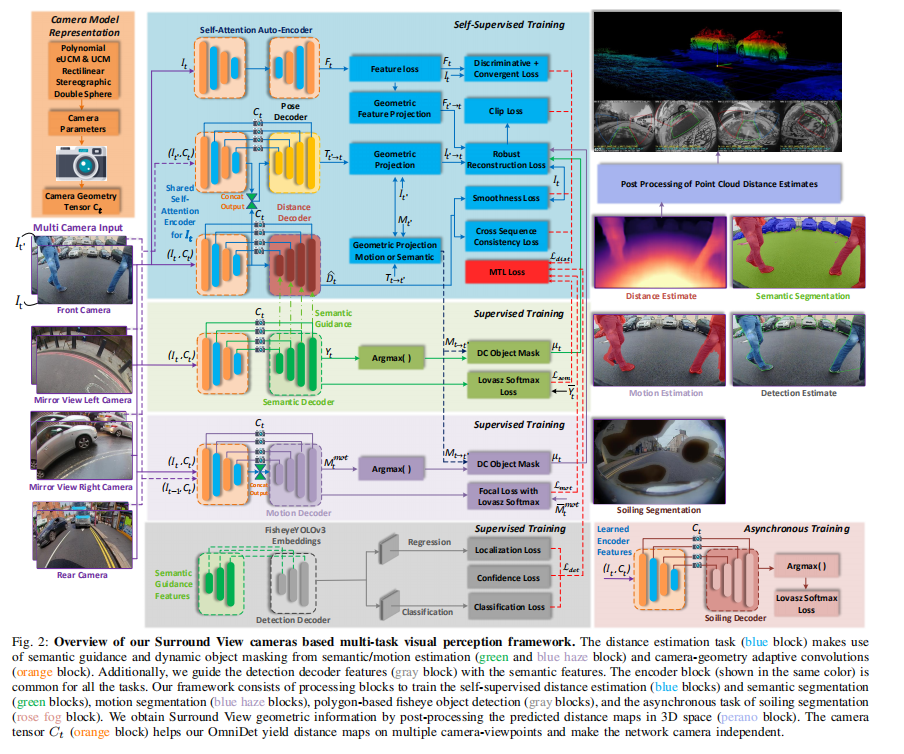
环视鱼眼镜头通常部署在自动驾驶中,以对车辆周围的360°近场进行感应。这项工作在未矫正的鱼眼图像上提供了一个多任务视觉感知网络,以使车辆能够感知其周围环境。它包括自动驾驶系统必需的六个主要任务:深度估计,视觉里程计,语义分割,运动分割,目标检测和镜头污染检测。我们证明了联合训练的模型比各自的单个任务版本执行得更好。我们的多任务模型具有共享的编码器,该编码器提供了显著的计算优势,并具有协同解码器,任务相互支持。我们提出了一种新颖的基于摄像机几何的自适应机制,以在训练和推理时对鱼眼失真模型进行编码。这对于在WoodScape数据集上进行训练至关重要,该数据集由来自世界不同地区的数据组成,这些数据是由安装在三辆具有不同内在特性和视点的不同汽车上的12台不同摄像机收集的。鉴于边界框不是变形的鱼眼图像的良好表示,我们还将目标检测扩展为使用具有非均匀采样顶点的多边形。我们还根据标准汽车数据集(即KITTI和Cityscapes)评估了模型。我们获得了有关深度估计的KITTI的最新结果,并且进行了姿势估计任务以及其他任务的竞争表现。我们对各种架构选择和任务加权方法进行了广泛的消融研究。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢