
论文标题:Temporal Memory Attention for Video Semantic Segmentation 论文链接:https://arxiv.org/abs/2102.08643 作者单位:中科院 & 国科大 作者称这是首个将memory和自注意力机制应用于视频语义分割的工作,表现SOTA!性能优于TDNet、PSPNet等网络。
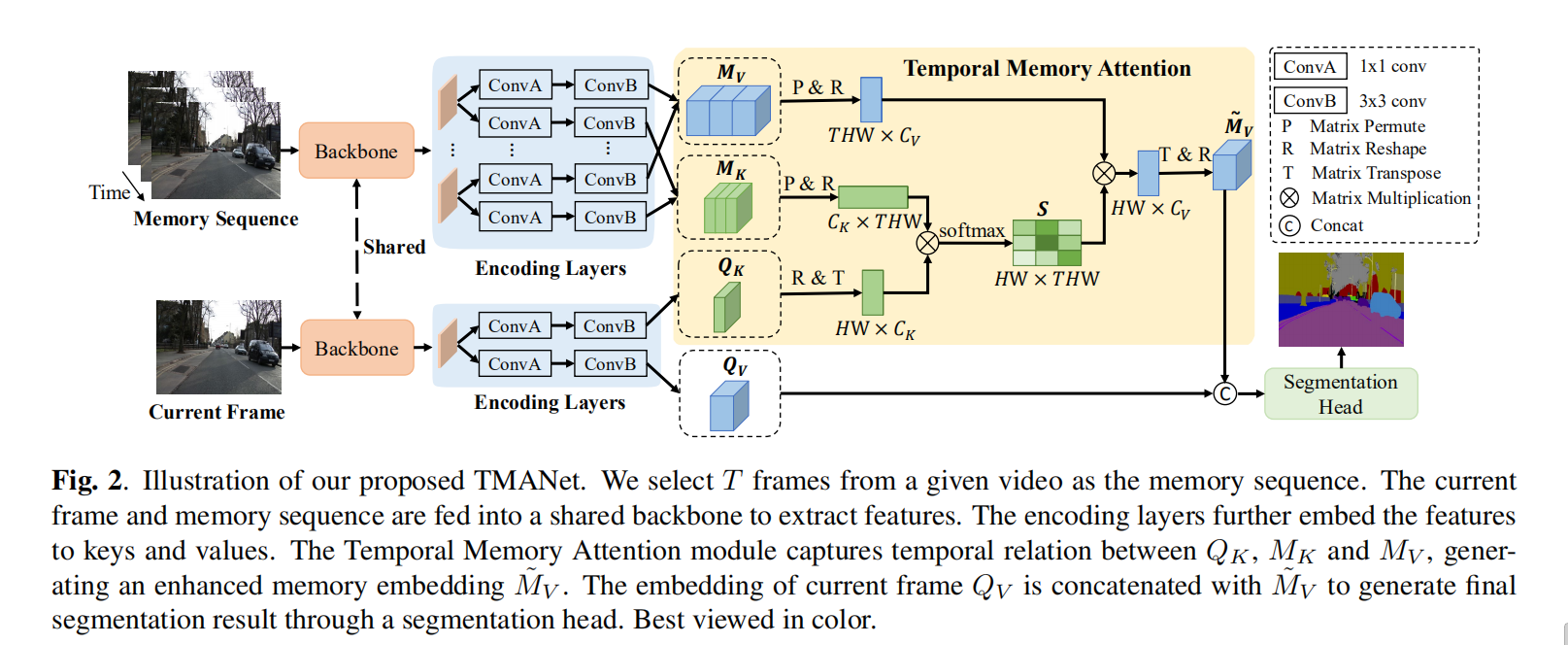
视频语义分割需要利用视频序列帧之间的复杂时间关系。先前的工作通常利用精确的光流来利用时间关系,而时间关系受制于沉重的计算成本。 在本文中,我们提出了一种时间记忆注意力网络(TMANet),该方法基于自注意力机制,无需详尽的光流预测,就可以自适应地整合视频序列上的long-range时间关系。特别地,我们使用几个过去的帧构造一个记忆器来记忆当前帧的时间信息。然后,我们提出一个时间记忆注意力模块,以捕获当前帧和记忆之间的关系,以增强当前帧的表示。 我们的方法在两个具有挑战性的视频语义分割数据集上实现了最新的性能,尤其是使用ResNet-50的Cityscapes的mIoU为80.3%,CamVid的76.5%mIoU。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢