
最近一篇来自OpenAI的关于预训练的论文Scaling Laws for Transfer在reddit上引发讨论。该工作 reddit上讨论网址:https://www.reddit.com/r/mlscaling/comments/lbeuj4/scalinglawsfortransferhernandezetal2021we/ 作者:Danny Hernandez, Jared Kaplan, Tom Henighan, Sam McCandlish,来自OpenAI
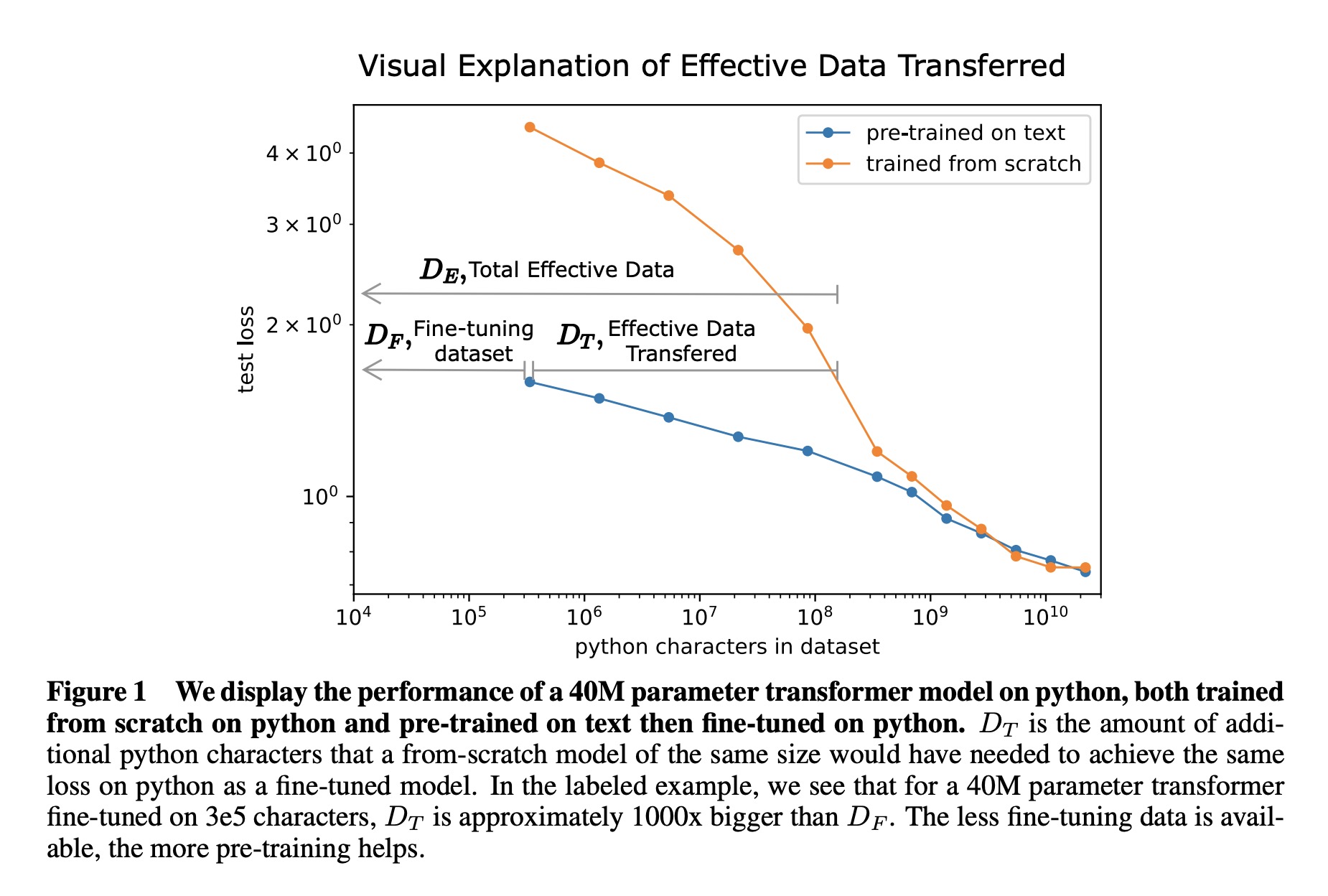
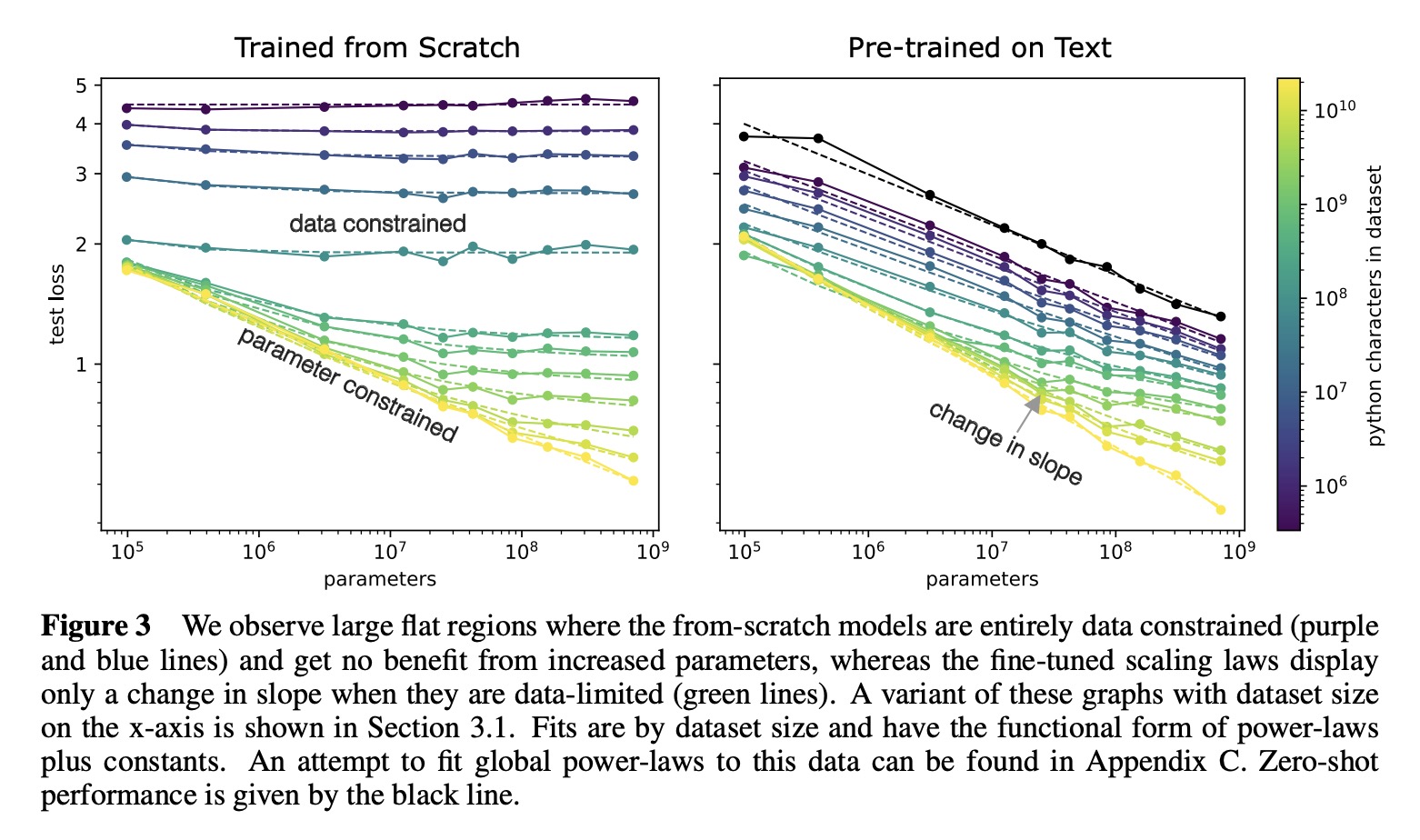
作者研究在无监督、微调设置下分布之间迁移学习的经验规律。在一个固定大小的数据集上从零开始训练越来越大的神经网络时,会受到数据限制,性能也会随着模型越来越大而停止改进(交叉熵损失)。
在大型语言数据集上预训练过的模型,性能增益的斜率只是减少了,而不是变为零。
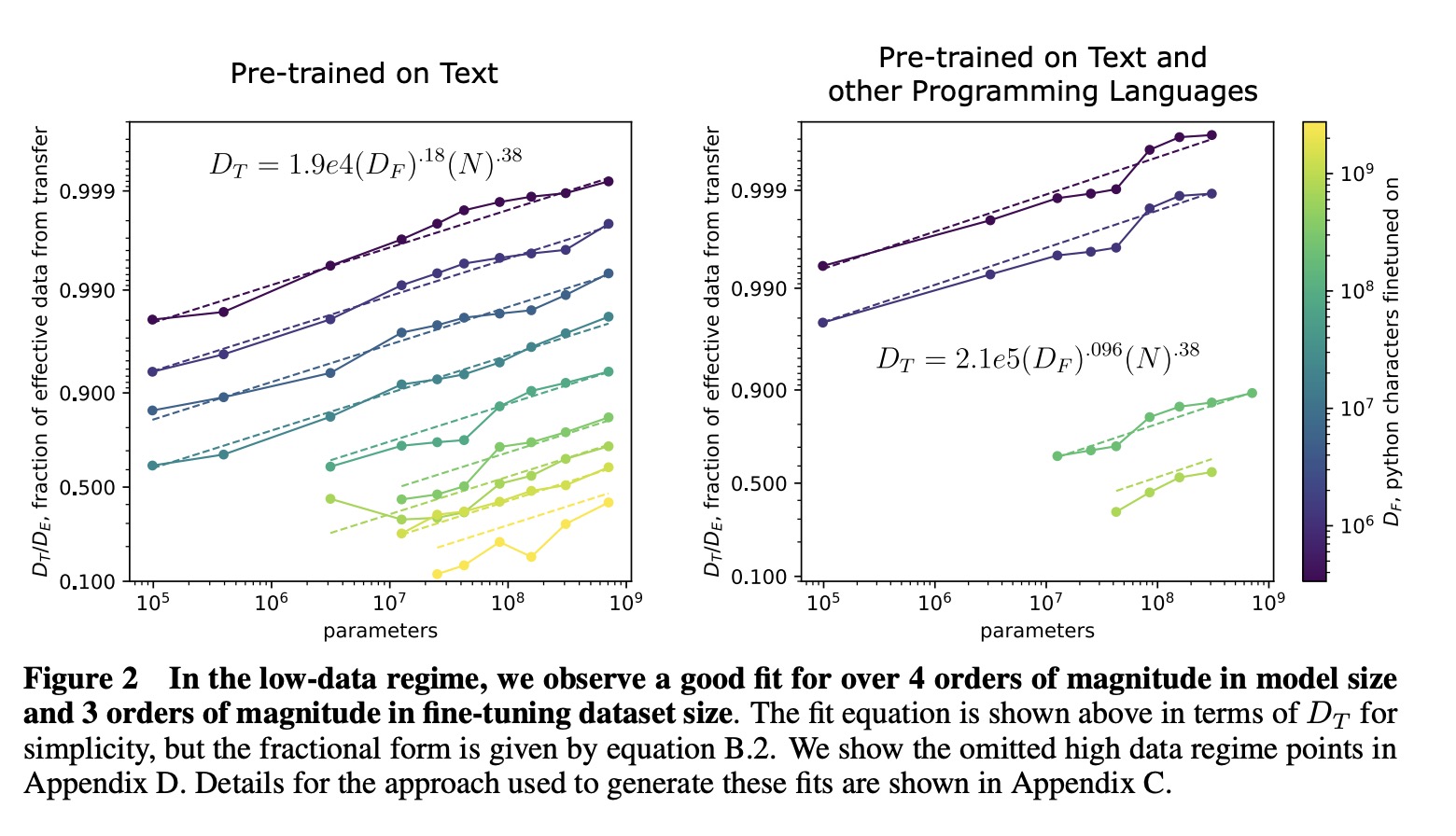
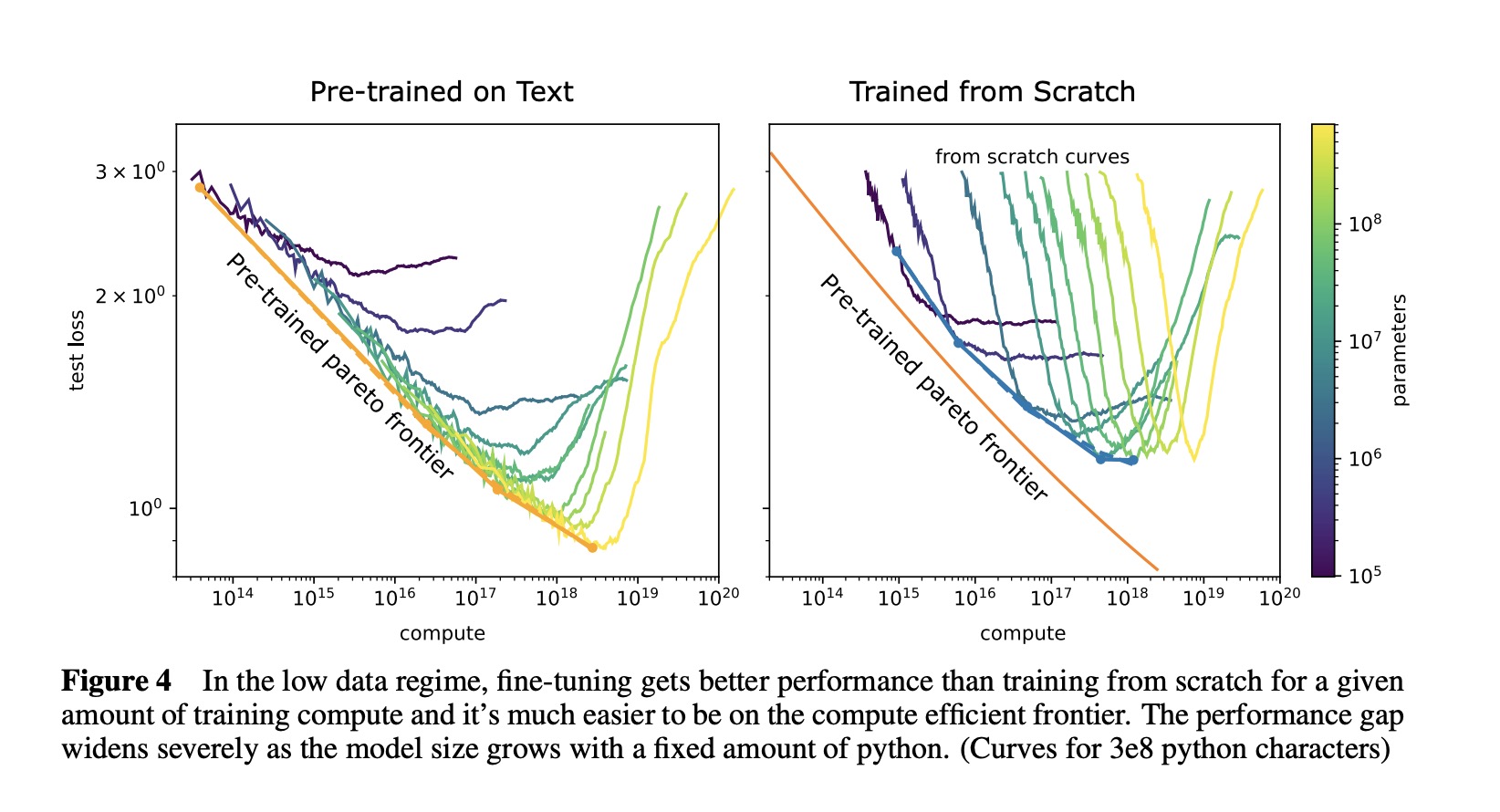
作者研究预训练状况下“转移”的有效数据的能力,方法是确定从零开始训练时,相同大小的transformer模型需要多少数据才能实现相同的损失。实验发现,预训练有效地“增加”了微调时数据集的大小。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢