
论文:Discovering Diverse Multi-Agent Strategic Behavior via Reward Randomization 作者:Zhenggang Tang*, Chao Yu*, Boyuan Chen, Huazhe Xu, Xiaolong Wang, Fei Fang, Simon Shaolei Du, Yu Wang, Yi Wu (*equal contribution) 时间:08 Jan 2021 发表情况:ICLR2021 点击查看ICLR open review 项目地址:https://sites.google.com/view/staghuntrpg
One-sentence Summary:论文提出了一个在reward-space进行探索的算法--RPG(Reward-Randomized Policy Gradient),通过RPG可以在具有挑战性的多智能体任务中发现多样化的策略,实验结果表明RPG的表现显著优于经典的policy/action-space探索的算法。
内容简介:
在卢梭《论人类不平等起源》中提到这样一个猎鹿(StagHunt)故事:一群猎人安静地在陷阱旁等待鹿的出现,这个时候一只兔子出现了,于是每一个猎人有了两个选择:继续等待鹿的出现还是立刻猎杀兔子?如果只考虑2个猎人的情况,就引出了一个2x2矩阵形式的StagHunt游戏(Table1,其中a>b>=d>c)。在这个任务中存在两个纯策略纳什均衡(Nash Equilibrium,NE):一个是两个猎人都选择等待鹿(Stag NE),这是一个风险很高的合作策略,但是每一个猎人都可以得到很高的回报,;另一个是两个猎人都等待兔子(Hare NE),这是一个保守的策略,但是每个猎人只能得到较低的回报。那么在这个任务中,现有的强化学习算法会收敛到哪个NE呢?实验结果表明,现有的算法总是会收敛到回报较低的Hare NE。为了解决这个问题,本文提出了一个简单有效的技术,Reward Randomization(RR),RR可以在多智能体任务中发现多样性的策略。将RR和策略梯度法相结合,论文提出一个在reward-space进行探索的新算法RPG(Reward-Randomized Policy Gradient),并且在存在多个NE的挑战性的多智能任务中(GridWorld和Agar.io)进行了实验验证,实验结果表明,RPG的表现显著优于经典的policy/action-space探索的算法。除此之外,论文进一步提出了RPG算法的扩展:利用RR得到的多样性策略池训练一个新的具备自适应能力的策略。

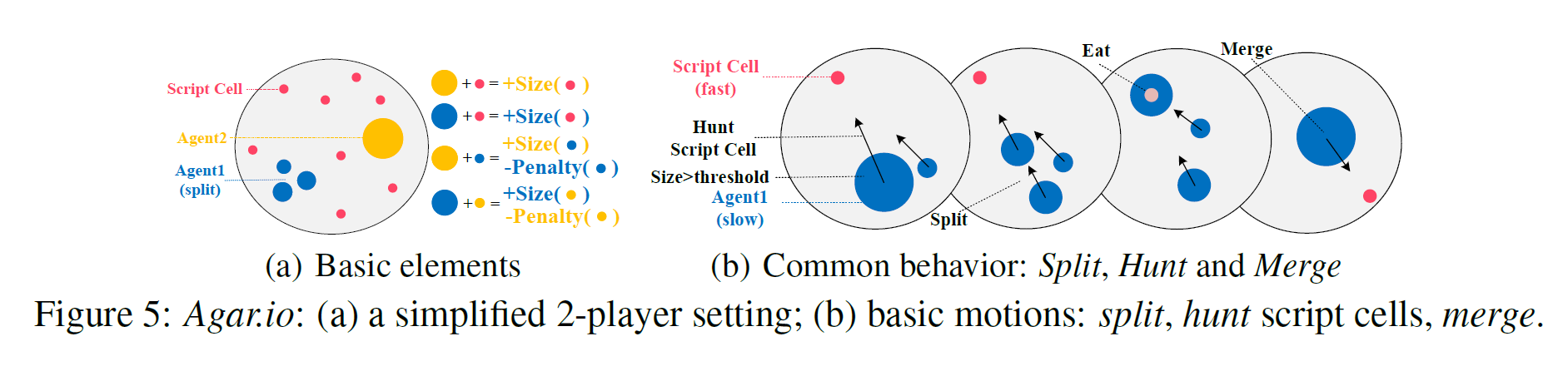
另外,论文的一个贡献是开源了一个新的多智能体环境 Agar.io(Figure 5)。Agar.io是一个非常流行的在线多玩家游戏(http://agar.io),每个玩家通过鼠标控制运动方向来吃掉比自己小的智能体,体积越大,奖励越高。论文通过RPG算法在Agar.io环境中发现了很多有趣、令人惊讶的策略行为,例如Sacrifice(献祭)和Perpetual(永动机)策略,感兴趣的读者可以戳原文。
点击此处展开英文摘要
We propose a simple, general and effective technique, Reward Randomization for discovering diverse strategic policies in complex multi-agent games. Combining reward randomization and policy gradient, we derive a new algorithm, Reward-Randomized Policy Gradient (RPG). RPG is able to discover a set of multiple distinctive human-interpretable strategies in challenging temporal trust dilemmas, including grid-world games and a real-world game Agar.io, where multiple equilibria exist but standard multi-agent policy gradient algorithms always converge to a fixed one with a sub-optimal payoff for every player even using state-of-the-art exploration techniques. Furthermore, with the set of diverse strategies from RPG, we can (1) achieve higher payoffs by fine-tuning the best policy from the set; and (2) obtain an adaptive agent by using this set of strategies as its training opponents.内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢