
近日,Facebook、哥伦比亚大学、佐治亚理工学院和达特茅斯大学的研究人员开发了Vx2Text——一个从视频、语音或者音频中生成文本的框架。他们声称,相比之前的最先进的方法,Vx2Text可以更好地创建说明文字并回答问题。
- 论文名称:Vx2TEXT: ENd-To-End Learning of Video-Based Text Generation From Multimodal Inputs
- 论文链接:https://arxiv.org/pdf/2101.12059.pdf
与大多数人工智能系统不同,人类可以很自然地轻易理解文本、视频、音频和图像在上下文语境中的含义。例如,一些给定的文本和图像,在分开讨论的时候似乎无害,比如“看看有多少人爱你”和一张贫瘠沙漠的图片,然而,人们会立即意识到,这些元素在结合在一起的时候,其实是具有潜在伤害性的。多模态学习可以包含一些潜在互补的信息或者趋势,不过,只有在学习中完全包含相关信息的时候,这些含义才能显现。
对于Vx2Text,,“模态独立“的分类器将来自视频、文本或音频的语义信号,转换为公共语义语言空间,这使得语言模型能够直接解释多模态数据,从而为通过谷歌的T5等强大的语言模型进行多模态融合——即结合信号来支持分类——提供了可能。Vx2Text中的生成式文本解码器,将编码器计算的多模态特征转换为文本,使该框架适合于生成自然语言语义概括。
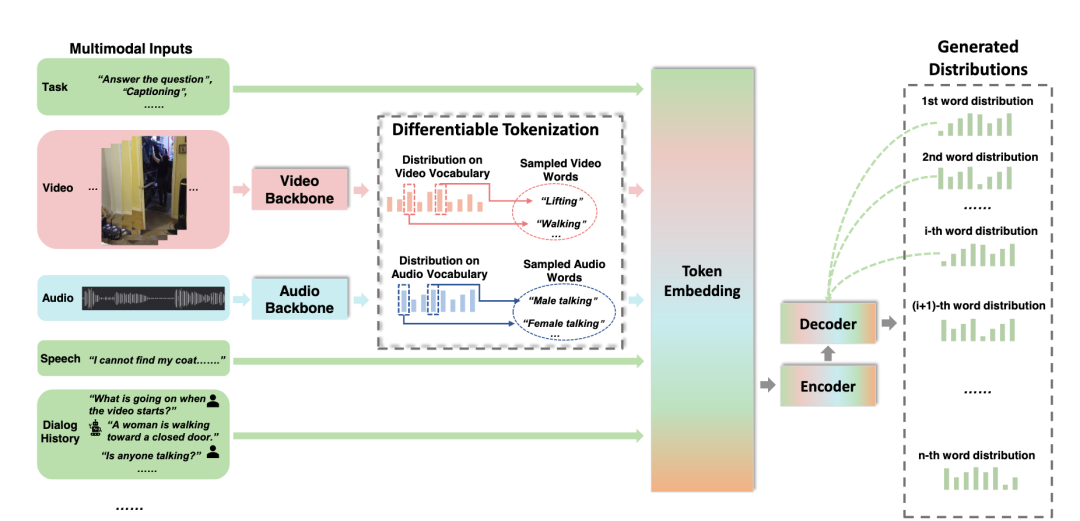
更多分析可以戳原文。
来源:新智元
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢