
来源: 王喆的机器学习笔记
为什么Embedding冷启动问题那么不好解决?以最简单的Word2vec为例(其他所有Embedding方法,不管多复杂,都遵循同样的原则),训练它的最终目的是要得到与onehot输入对应的向量,用这个Embedding向量来表示一个用户,或者一个物品,或者一个特定的特征。
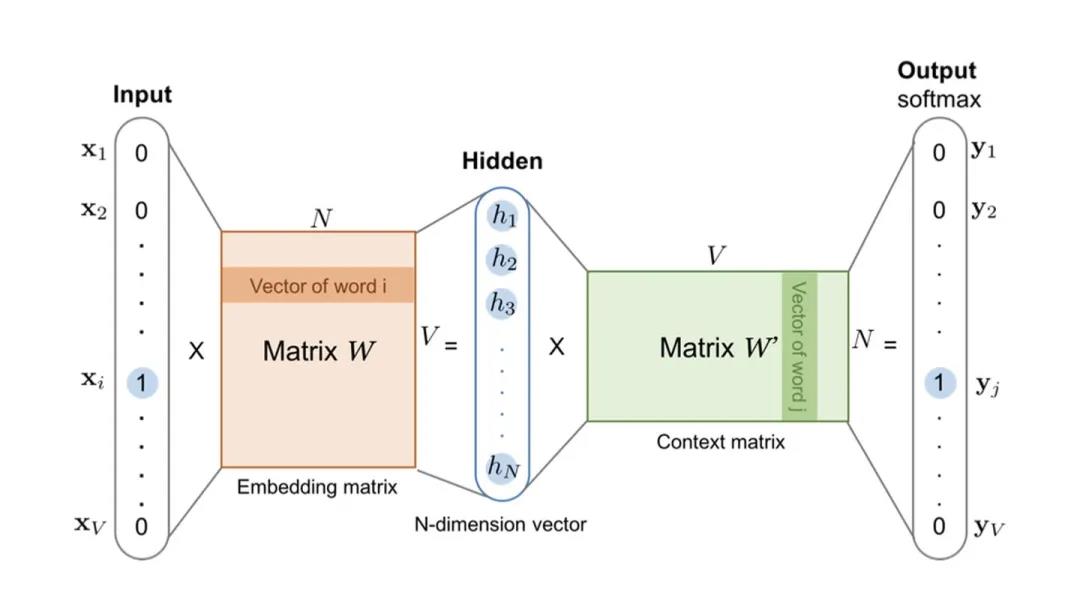
为了生成这样一个Embedding向量,我们就必须完成整个神经网络的训练,拿上面的Word2vec的结构图来说,你必须在Embedding matrix W训练完毕、收敛之后,才能够提取对应的Embedding。
这个时候冷启动的问题就来了:如果在模型训练完毕之后,又来了一个新的user或者item,要想得到新的Embedding,就必须把这个新的user/item加到网络中去。这就意味着你要更改输入向量的维度,这进一步意味着你要重新训练整个神经网络。但是,由于Embedding层的训练往往是整个网络中参数最大,速度最慢的,整个训练过程持续几个小时是非常常见的。这个期间,肯定又有新的item产生,难道整个过程就成一个死局了吗?这个所谓的“死局”就是棘手的Embedding的冷启动问题。
从整个深度学习推荐系统的框架角度解决这个问题,可以从四个角度考虑:
- 1.信息和模型
- 2.补充机制
- 3.工程框架
- 4.跳出固有思维
本文接下来也将围绕这四个角度进行展开,感兴趣的可以继续戳原文。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢