
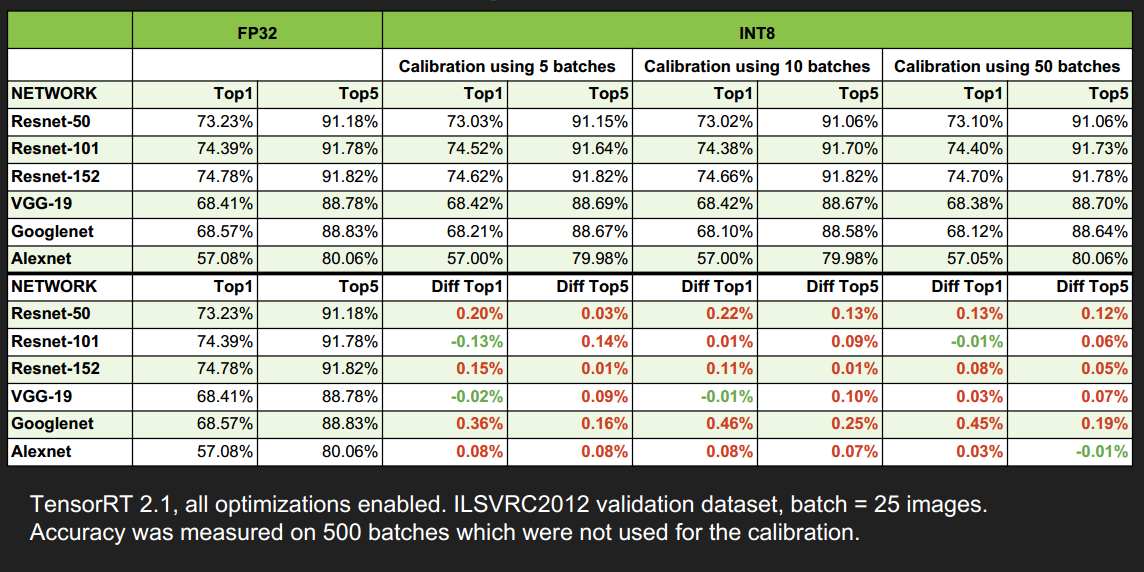
现有的深度学习框架 比如:TensorFlow,pytorch,Caffe, MixNet等,在训练一个深度神经网络时,往往都会使用 float 32(Full Precise ,简称FP32)的数据精度来表示,权值、偏置、激活值等。但是如果一个网络很深的话,比如像VGG,ResNet这种,网络参数是极其多的,计算量就更多了(比如VGG 19.6 billion FLOPS, ResNet-152 11.3 billion FLOPS)。如此多的计算量,如果中间值都使用 FP 32的精度来计算的话,势必会很费时间。而这对于嵌入式设备或者移动设备来说,简直就是噩梦,因为他们的计算能力和内存数量是不能与PC相比的。
因此解决此问题的方法之一就是在部署推理时(inference)使用低精度数据,比如INT8。除此之外,当然还有模型压缩之类的方法,不过此处不做探究。注意此处只是针对 推理阶段,训练时仍然使用 FP32的精度。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢