

作为机器学习的一大关键领域,强化学习侧重如何基于环境而行动,其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。
但是,这种算法思路有着明显的短板:许多成功案例都要通过精心设计、信息量大的奖励机制才能实现,当遇到很少给予反馈的复杂环境时,强化学习算法就很容易碰壁。因此,过往的 AI 难以解决探索困难(hard-exploration)的问题,这类问题通常伴随着奖励稀疏(sparse)且会有欺骗性(deceptive)的奖励存在。
昨日,一项发表在《自然》(Nature)杂志的研究提出了一类全新的增强学习算法,该算法在雅达利(Atari 2600)经典游戏中的得分超过了人类顶级玩家和以往的 AI 系统,在《蒙特祖马的复仇》(Montezuma’s Revenge)和《陷阱》(Pitfall!)等一系列探索类游戏中达到了目前最先进的水平。

论文的主要作者来分别来自 OpenAI 和 Uber AI Labs,他们将这类算法统称为 Go-Explore,该类算法改善了对复杂环境的探索方式,或是 AI 向真正智能学习体进化迈出的重要一步。
Go-Explore 的算法逻辑
论文作者埃科菲特和同事们分析认为,有两个主要问题阻碍了以前算法的探索能力。
第一是 “分离”(detachment),算法过早地停止返回状态空间的某些区域,尽管有证据表明这些区域仍是有希望的。
第二个是 “脱轨”(derailment),算法的探索机制阻止智能体返回到以前访问过的状态,直接阻止探索或迫使将探索机制最小化,从而不会发生有效的探索。
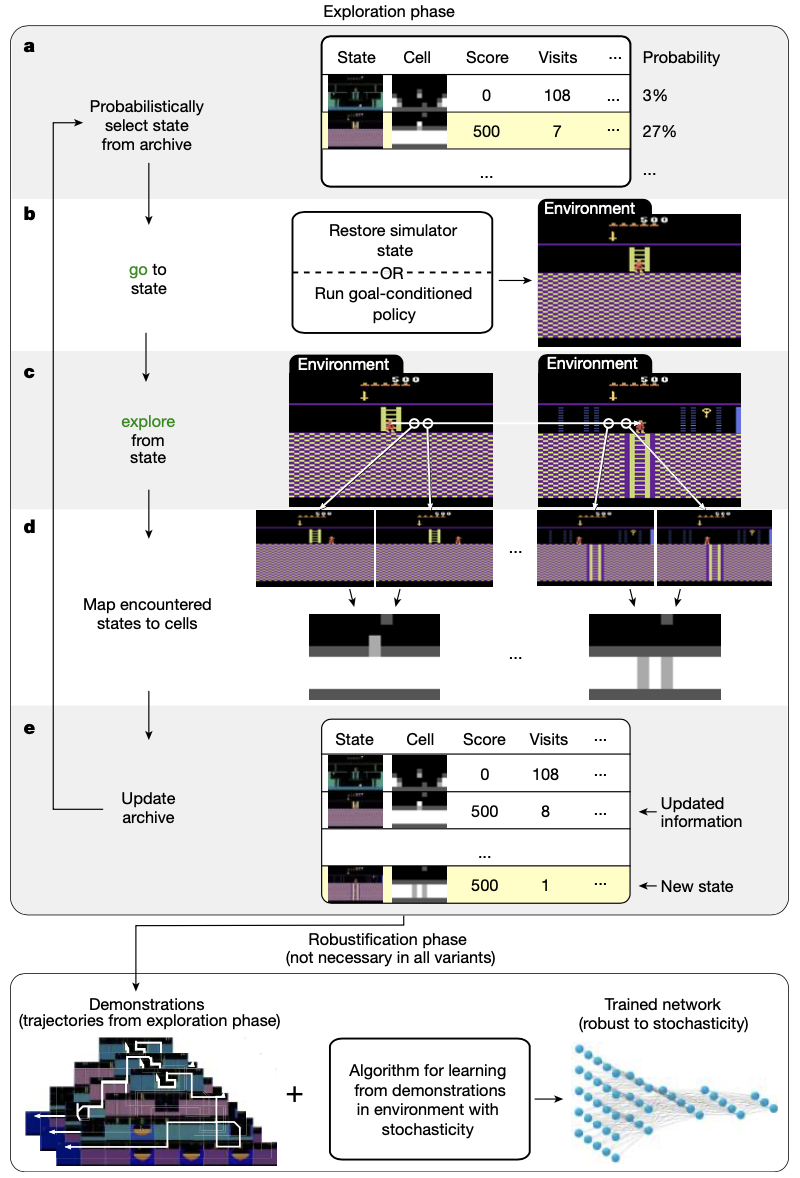
为了避免分离,Go-Explore 建立了一个智能体在环境中访问过的不同状态的 “档案”,从而确保状态不会被遗忘。如下图,从一个只包含初始状态的存档开始,它不断迭代构建这个存档。
 图|Go-Explore 方法概览(来源:Nature)
图|Go-Explore 方法概览(来源:Nature)
首先,它可能从存档中选择要返回的状态(a),返回到所选状态(b),然后从该状态探索(c),将返回和探索过程中遇到的每个状态映射到低维单元表示(d),用遇到的所有新状态更新存档(e)。
整个过程让人想起经典的规划算法,在深度强化学习研究中,这些算法的潜力相对未被重视。然而,对于强化学习领域所关注的问题(如上述在 Atari 游戏中的探索困难问题),这些问题是高维的,具有稀疏的奖励和 / 或随机性,没有已知的规划方法是有效的,且由于需要探索的状态空间太大,无法进行彻底搜索,而随机转换使得不可能知道节点是否已经完全扩展。
在Atari benchmark 套件平台测试中,Go-Explore 的平均表现都是 “超级英雄”,在 11 个游戏比赛测试中都超过了之前算法的最高水平。
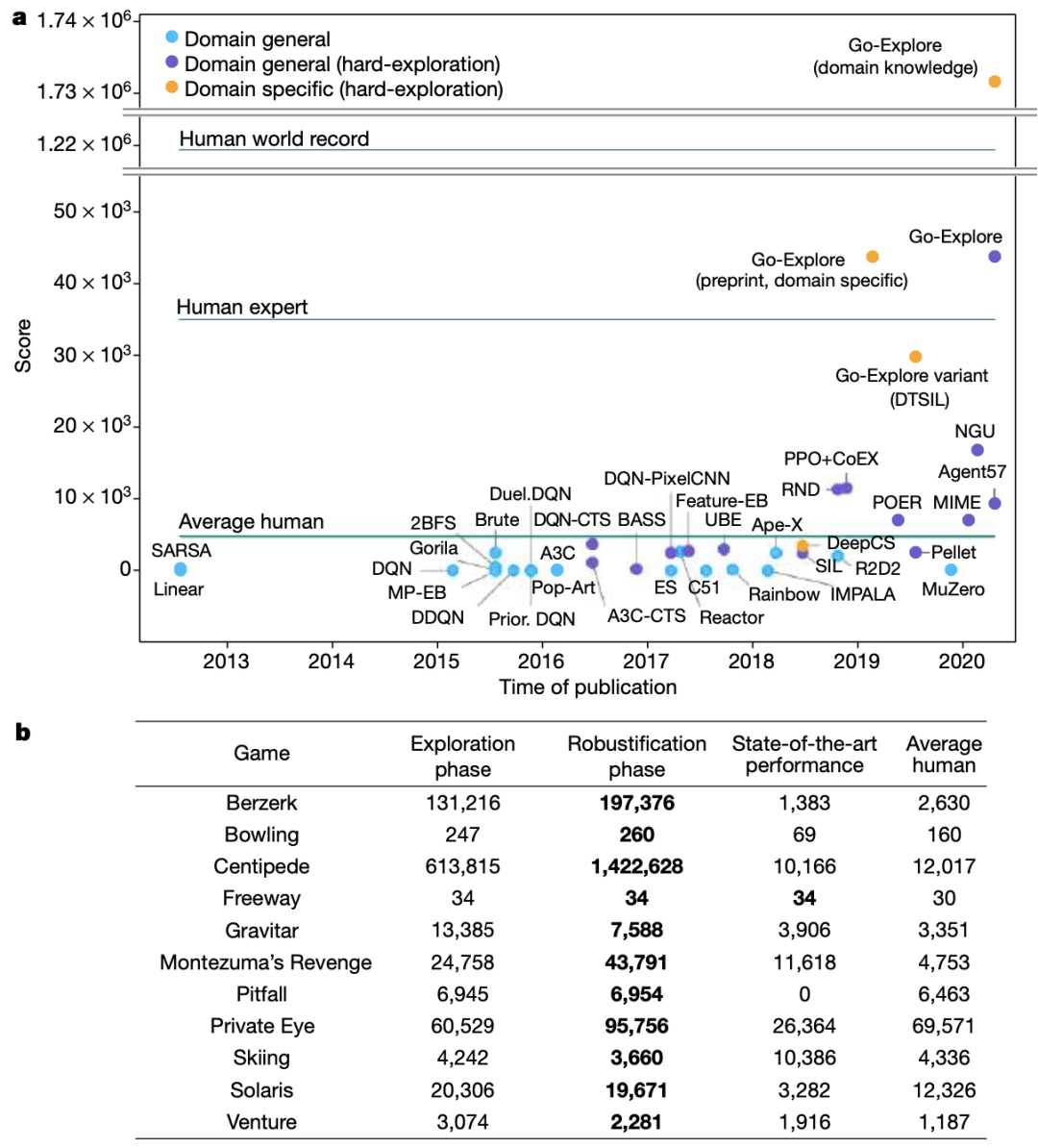 图|Go-Explore 在 Atari 平台游戏中的强力表现(来源:Nature)
图|Go-Explore 在 Atari 平台游戏中的强力表现(来源:Nature)
研究人员表示,这项工作提出的 Go-Explore 算法家族的有效性表明,它将在许多领域取得进展,包括机器人技术、语言理解和药物设计等,论文中提到的实例只代表了 Go-Explore 可能实现的一小部分能力,为未来的算法研究打开许多令人兴奋的可能性。
论文地址:https://www.nature.com/articles/s41586-020-03157-9
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢