
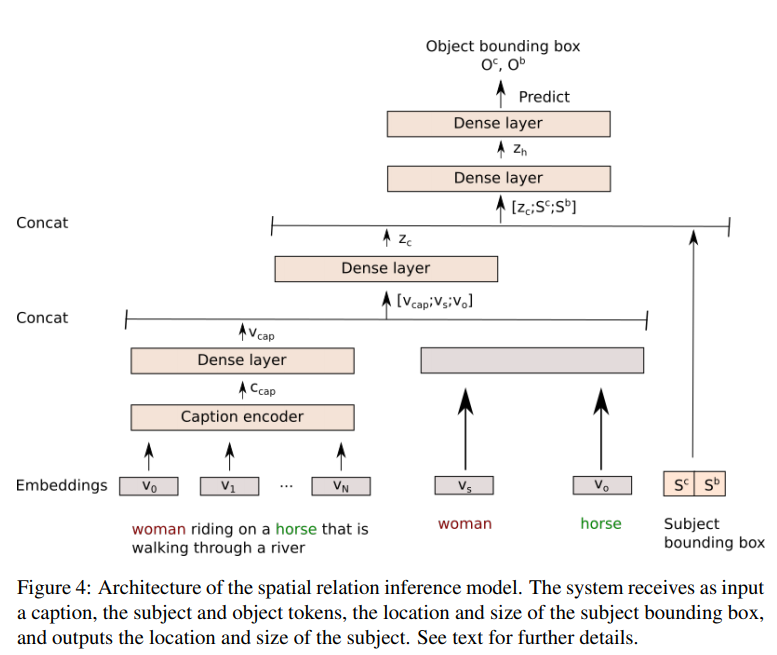
【论文标题】Inferring spatial relations from textual descriptions of images 【作者团队】A Elu, G Azkune, O L d Lacalle, I Arganda-Carreras, A Soroa, E Agirre 【发表时间】2021/2/1 【机构】University of the Basque Country UPV/EHU 【论文链接】https://arxiv.org/pdf/2102.00997.pdf 【代码链接】https://github.com/ixa-ehu/rec-coco 【推荐理由】本文收录于Pattern Recognition,文章表明使用图像的完整文字描述可提高对图像实体之间的空间关系建模的能力,并发布了一个新的数据集。 根据文本描述生成图像需要一定程度的语言理解和有关所描述物理实体空间关系的常识知识。在这项工作中,作者专注于推断实体之间的空间关系,这是基于文本组成场景的过程中的关键步骤。更具体地说,给定一个标题,其中包含对主题的提及以及该主题的边框的位置和大小,我们的目标是预测该标题中提及的对象的位置和大小。以往的工作都没有使用文本描述信息,而是使用手动提供的主题和对象之间的关系。然而,实际上使用的评估数据集包含手动注释的本体三元组,却没有图像文本描述,这使得实际操作起来不现实。基于此,作者提出了一个使用完整字幕和字幕中的关系(REC-COCO)的系统,这个数据集来自MS-COCO,可以直接评估字幕中的空间关系推断。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢