
【论文标题】Calibrate Before Use: Improving Few-Shot Performance of Language Models
【作者团队】T Z. Zhao, E Wallace, S Feng, D Klein, S Singh
【发表时间】2021/2/19
【机构】UC Berkeley & University of Maryland & UC Irvine
【论文链接】https://arxiv.org/pdf/2102.09690.pdf
【代码链接】https://www.github.com/tonyzhaozh/few-shot-learning
【推荐理由】本文来自于加州大学伯克利分校,文章提出了一种上下文校准程序用于解决少样本学习中的不稳定性。
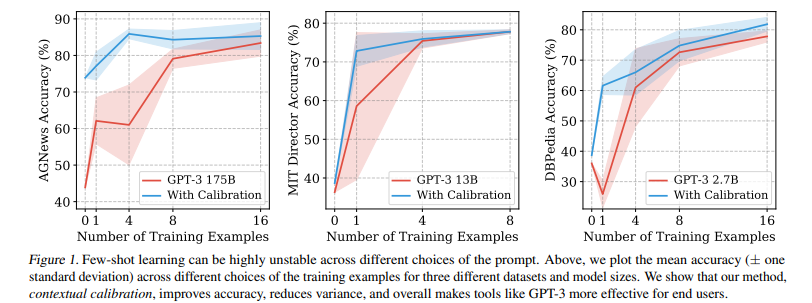
只要提供包含少数训练样本的自然语言提示,GPT-3就能执行许多任务,但这种类型的少样本学习可能是不稳定的:提示格式的选择、训练样本、甚至训练样本顺序都可能导致准确性在接近偶然到接近最先进水平之间漂移,这种不稳定性源于语言模型对预测某些答案的偏差,例如,那些被放在提示语末尾附近的答案,或在预训练数据中常见的答案,这些偏差往往会导致模型的输出分布发生变化。为缓解这种情况,通过询问模型在给定训练提示和无内容测试输入(如 "N/A")时对每个答案的预测,来估计模型对每个答案的偏差,对校准参数进行拟合,使无内容输入的每个答案具有统一的分数。这种上下文校准程序提供了一个良好的校准参数设置,无需额外的训练数据。在不同任务集上,这种上下文校准程序大幅提高了GPT-3和GPT-2的平均准确率(绝对值高达30.0%),并降低了提示不同选择的差异。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢