
【论文】GraphCodeBERT: Pre-training Code Representations with Data Flow 【作者】Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, Michele Tufano, Shao Kun Deng, Colin Clement, Dawn Drain, Neel Sundaresan, Jian Yin, Daxin Jiang, Ming Zhou 【代码】https://github.com/microsoft/CodeBERT 【单位】Sun Yat-sen University(中山大学),哈工大,微软 【时间】2020/12/17 【发表情况】ICLR2021
本文提出GraphCodeBERT,一个考虑了结构信息的编程语言预训练模型,利用结构信息后显著增加了模型的性能。
预训练编程语言模型在各种与代码相关的任务(如代码搜索、代码完成、代码总结等)上取得了显著的经验改进。然而,现有的预训练模型将代码片段视为标记序列,而忽略了代码的内在结构。这些结构提供了关键的代码语义,并能增强代码理解过程。
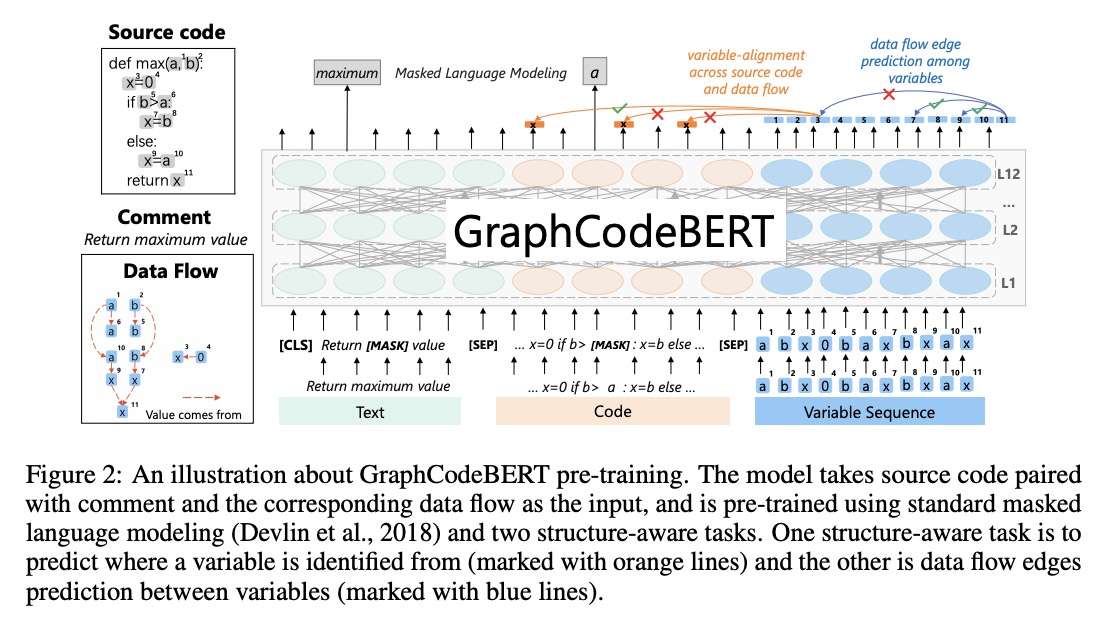
本文提出GraphCodeBERT,一种预训练编程语言模型,考虑了代码的内在结构。作者没有采用像抽象语法树(AST)那样的语法级代码结构,而是在预训练阶段使用数据流,这是一种语义级的代码结构,对变量之间的“值从哪里来”的关系进行编码。这样的语义级结构很简洁,不会带来不必要的AST层次结构,而AST的属性使模型更高效。作者开发了基于Transformer的GraphCodeBERT,除了使用掩蔽语言建模的任务外,还引入了两个结构感知的训练前任务。一种是预测代码结构的边缘,另一种是对齐源代码和代码结构之间的表示。在四个任务上评估模型,包括代码搜索、克隆检测、代码翻译和代码改进。
结果表明,代码结构和新引入的预训练任务可以改善GraphCodeBERT,并在四个下游任务上实现最先进的性能。作者进一步证明,在代码搜索任务中,模型更倾向于结构级的关注而不是token级的关注。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢