
【论文标题】Data Augmentation for Abstractive Query-Focused Multi-Document Summarization 【作者团队】Ramakanth Pasunuru,Asli Celikyilmaz,Michel Galley,Chenyan Xiong,Yizhe Zhang,Mohit Bansal,Jianfeng Gao 【发表时间】AAAI 2021 【机 构】微软研究院 【论文链接】https://arxiv.org/pdf/2103.01863.pdf
【推荐理由】针对以查询为中心的多文档摘要缺乏足够的大规模高质量的训练数据集问题,使用两种数据增强方法来构造两个QMDS训练数据集。实证结果表明,本文的数据增强和编码方法在自动度量以及沿着多个属性的人类评估上优于基线模型。
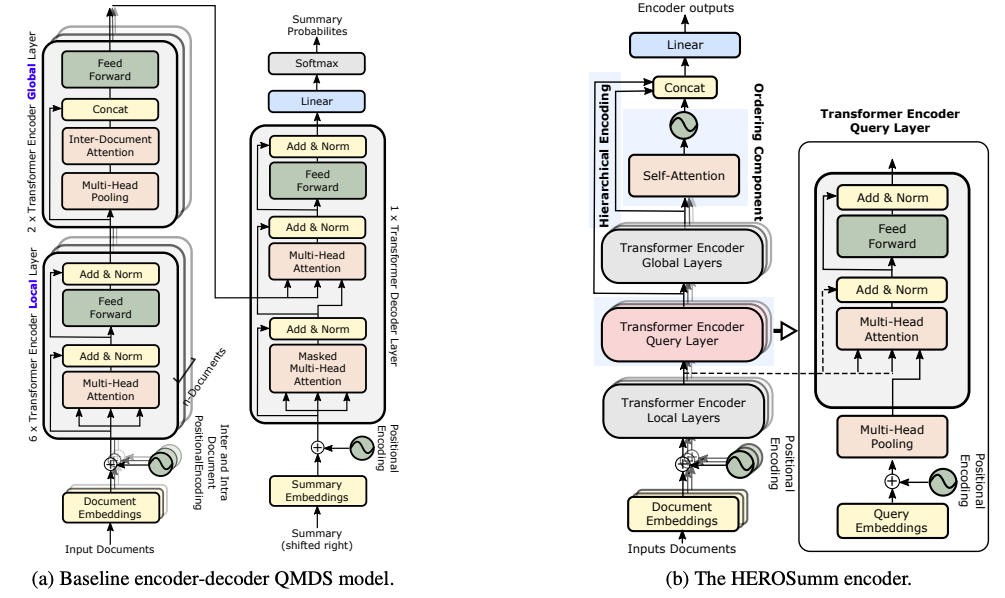 由于缺乏足够的大规模高质量的训练数据集,以查询为中心的多文档摘要的研究进展受到了一定的限制。我们提出了两个QMDS训练数据集,我们使用两种数据增强方法来构造它们:(1)传输常用的单文档CNN/每日邮件摘要数据集来创建QMDSCNN数据集,(2)挖掘搜索查询日志来创建QMDSIR数据集。这两个数据集具有互补的属性,即QMDSCNN有真实的摘要,但是查询是模拟的,而QMDSIR有真实的查询,但是模拟的摘要。为了涵盖这些真实的总结和查询方面,我们在组合数据集上建立了抽象的端到端神经网络模型,在DUC数据集上产生新的最先进的传输结果。我们还引入了新的分层编码器,可以更有效地对多个文档进行查询编码。实证结果表明,我们的数据增强和编码方法在自动度量以及沿着多个属性的人类评估上优于基线模型。
由于缺乏足够的大规模高质量的训练数据集,以查询为中心的多文档摘要的研究进展受到了一定的限制。我们提出了两个QMDS训练数据集,我们使用两种数据增强方法来构造它们:(1)传输常用的单文档CNN/每日邮件摘要数据集来创建QMDSCNN数据集,(2)挖掘搜索查询日志来创建QMDSIR数据集。这两个数据集具有互补的属性,即QMDSCNN有真实的摘要,但是查询是模拟的,而QMDSIR有真实的查询,但是模拟的摘要。为了涵盖这些真实的总结和查询方面,我们在组合数据集上建立了抽象的端到端神经网络模型,在DUC数据集上产生新的最先进的传输结果。我们还引入了新的分层编码器,可以更有效地对多个文档进行查询编码。实证结果表明,我们的数据增强和编码方法在自动度量以及沿着多个属性的人类评估上优于基线模型。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢