
如何才能让强化学习收敛到收益最优的策略呢?为了解决这个问题,来自清华大学、北京大学、UC 伯克利等机构的研究者提出了一个简单有效的技术,奖励随机化(Reward Randomization,RR)。不同于传统强化学习中的在状态空间(state-space)中进行探索(exploration)的方法,奖励随机化是一个在奖励空间(reward-space)进行探索的方法。这项研究已被 ICLR 2021 大会接收为 Poster 论文。
论文地址:https://arxiv.org/abs/2103.04564
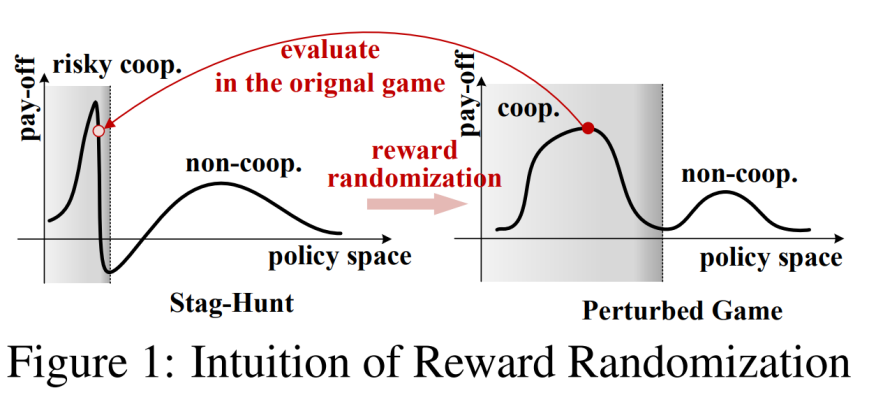
如下图所示,在一个奖励设置比较极端的游戏里,强化学习通常很难探索到最优策略(左图,灰色区域表示可能收敛到最优解的子空间,由于奖励极端而非常狭小);但是同样的策略在其他奖励设置的游戏中可能很容易被探索到(右图)。这就演变出论文的核心观点:通过奖励随机化对原始游戏(StagHunt)的奖励(reward)进行扰动,将问题转化为在扰动后的游戏中寻找合作策略,然后再回到原始游戏中进行微调(fine-tune),进而找到最优策略。
进一步地,论文将奖励随机化和策略梯度法(Policy Gradient,PG)相结合,提出一个在 reward-space 进行探索的新算法 RPG(Reward-Randomized Policy Gradient)。实验结果表明,RPG 的表现显著优于经典的 policy/action-space 探索的算法,并且作者还利用 RPG 发现了很多有趣的、人类可以理解的智能体行为策略。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢