
【论文标题】A Vision Based Deep Reinforcement Learning Algorithm for UAV Obstacle Avoidance 【作者团队】Jeremy Roghair, Kyungtae Ko, Amir Ehsan Niaraki Asli, Ali Jannesari 【发表时间】2021/03/11 【机 构】美国爱荷华州立大学,计算机科学系 【论文链接】https://arxiv.org/pdf/2103.06403.pdf
【推荐理由】本文出自美国爱荷华州立大学,针对于传统算法在无人机避障探索中总是获得稀少奖励的问题,提出了两种改进无人机避障探索的技术,与现有方法进行比较,平均奖励提高两倍。
强化学习与无人飞行器(UAV)的集成以实现自主飞行是近年来的活跃研究领域。一个重要的部分集中在无人机在环境中的导航中的障碍检测和避让。Deep Q-network(DQN)可以解决在看不见的环境中进行探索的问题。但是,对行为进行统一采样的价值探索可能会导致冗余状态,在这种状态下,环境通常固有地获得稀少奖励。为了解决这个问题,我们提出了两种改进无人机避障探索的技术。第一种是基于收敛的方法,该方法使用收敛误差遍历未探索的动作和时间阈值来平衡探索和利用。第二种是使用域网络的基于指导的方法,该域网络使用高斯混合分布将以前看到的状态与预测的下一个状态进行比较,以便选择下一个动作。这些方法的性能和评估是在多个3-D仿真环境中实现的,但复杂度有所不同。与现有技术相比,所提出的方法显示出平均奖励提高了两倍。
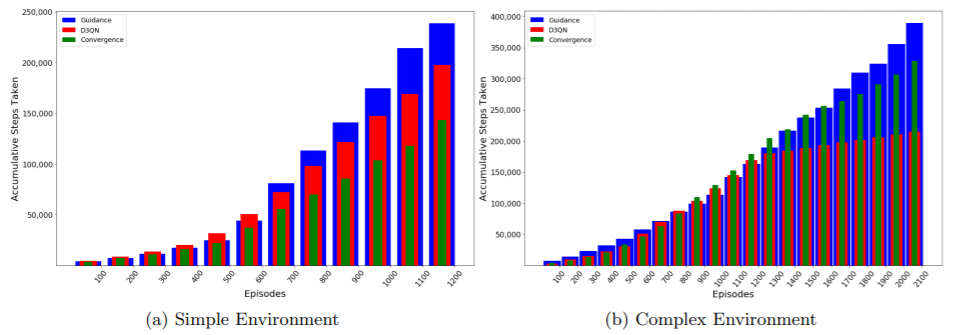
下图为在仿真环境结束之前采取的步骤。每种环境都再次表明,指导性探索的速度超过了D3QN,并且收敛性探索朝着探索更多状态空间的目标迈进。对于复杂的环境,可以从下图(b)推断出,与D3QN相比,指导探索正在朝着更少的碰撞和更高的收敛速度发展。 特别是对于最后100集,具有D3QN的特工平均采取50步后,具有指导探索策略的特工在终止前平均每集要执行350步。在简单环境中也存在相同的效果 但不太明显。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢