
深度学习模型在生产中越来越多地被用作应用程序的一部分,例如个人助理,自动驾驶汽车和聊天机器人。这些应用对模型的推理延迟提出了严格的要求。因此,生产中使用了各种各样的专用硬件,包括CPU,GPU和专用加速器,以实现低延迟推理。
对于具有递归和其他动态控制流的模型,减少推理延迟尤其困难。近日,华人AI新星、CMU助理教授陈天奇团队在arxiv上发表了针对深度学习开发的编译器「CORTEX」,侧重解决深度学习模型的优化问题,能够为递归神经网络生成高效的编码。这个编译器不依赖其他库,能够端到端地测量优化性能,最高降低了14倍推理延迟。
论文链接:https://arxiv.org/abs/2011.01383
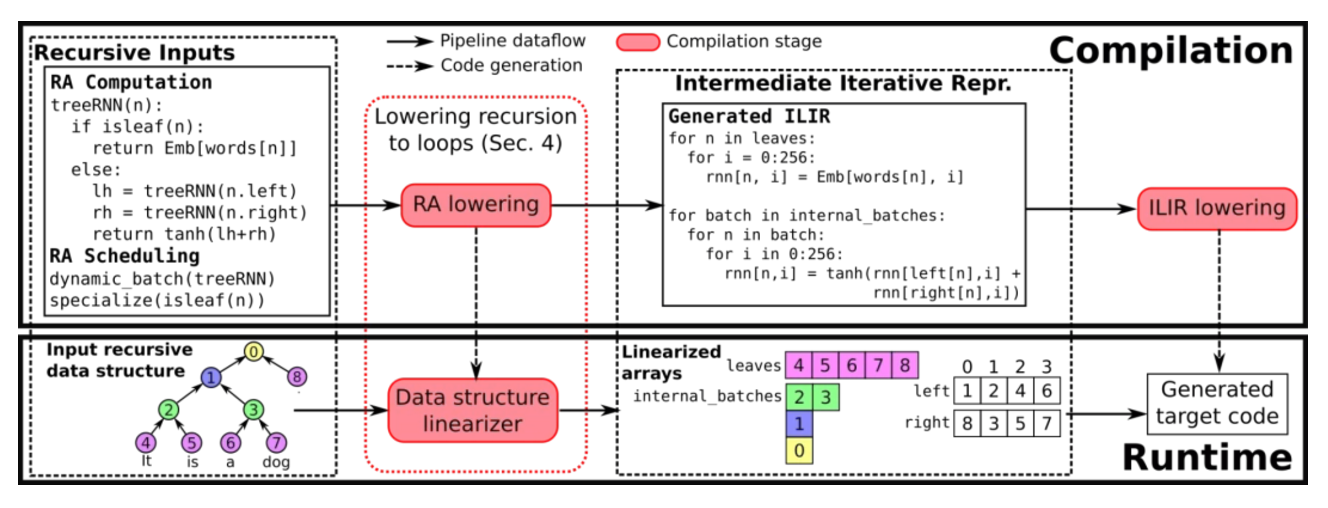
递归深度学习模型的编译器「CORTEX」旨在构建一个编译器和运行基础结构,以通过不规则和动态的控制流,甚至不规则的数据结构访问也能有效地编译ML应用程序。这种编译器方法和不依赖其他库,能够实现端到端优化,在不同backend上的推理延迟最多降低了14倍。
CORTEX包括一个运行框架,这个框架可以处理具有递归数据结构遍历的模型。这个框架能够从张量计算中完全解开递归遍历,并进行部分推理,从而能够快速地将整个张量计算放入到硬件加速器(目前支持CPU和GPU)。这意味着编译器可以生成一个高度优化的代码,能够避免加速器和主机CPU之间频繁通信的开销。
论文的贡献总结如下:
设计了CORTEX,一个基于编译器的框架,可实现端到端优化和高效的代码生成,以递归深度学习模型的低延迟推理。
作为设计的一部分,扩展了张量编译器,并提出了递归模型的新调度原语和优化。
对提出的框架进行原型设计,并根据最新的递归深度学习框架对其进行评估,并获得了显着的性能提升( 在Nvidia GPU,Intel和ARM CPU上最高可达14倍)。
来源: 新智元
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢