
论文:CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation 作者:Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting 机构:Google Research 时间:2021/03/11
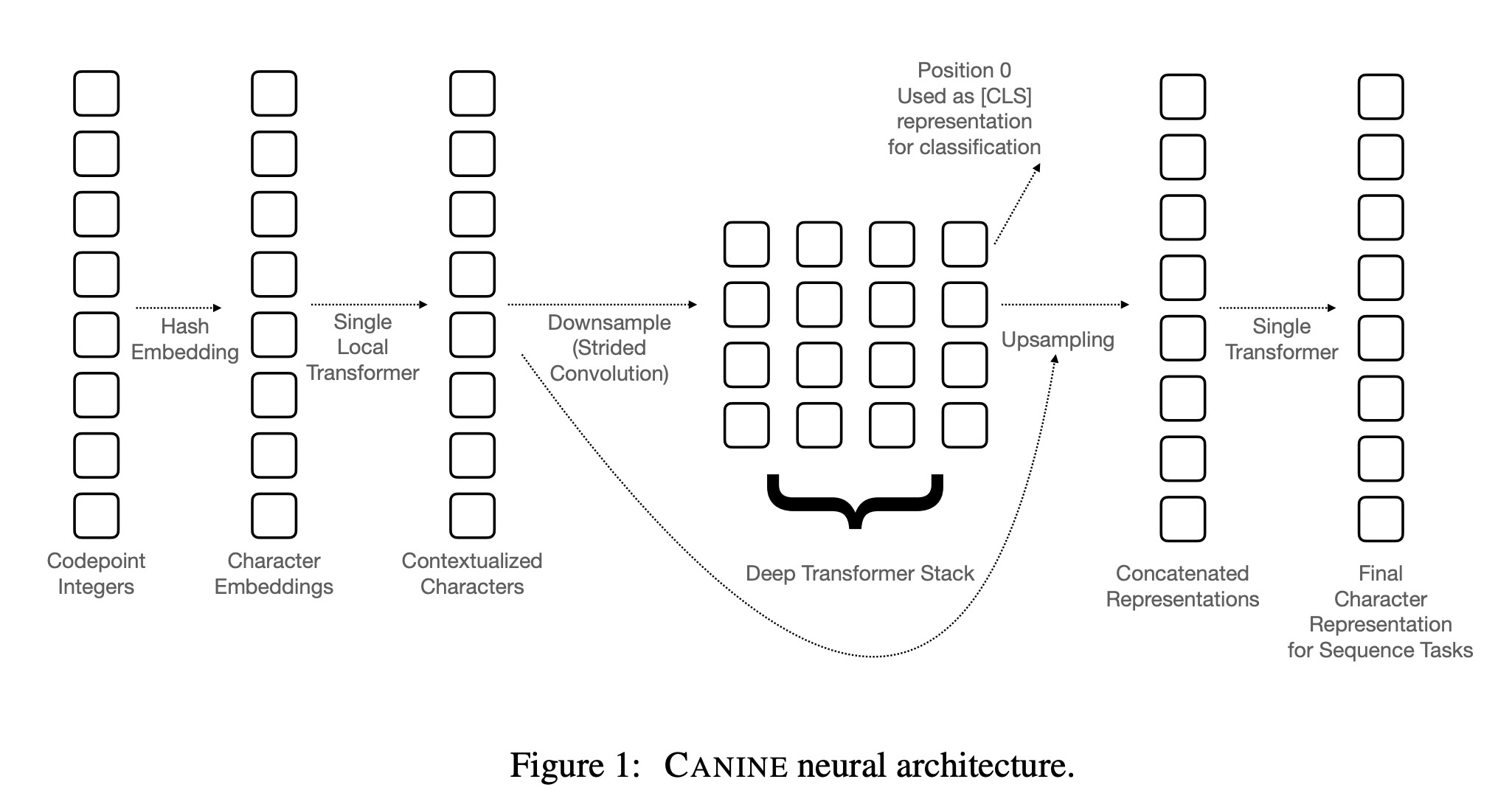
NLP系统在很大程度上已经被端到端神经模型取代,然而几乎所有常用的模型仍需要显式的tokenization的步骤。虽然最近基于数据驱动的子词词典的tokenization方法没有人工设计的方法那么脆弱,但是这些技术并不适用于所有语言,因为这种“通用性”其实会限制模型的适应能力。本文提出了CANINE,一种直接对字符序列进行tokenization操作的神经编码器,无需显式标记化。以及一种用软归纳偏差代替硬标记边界的预训练策略。为了有效和高效地使用它的细粒度输入,CANINE结合了downsampling(减少输入序列长度)和deep transformer stack(对上下文进行编码)。在TyDi QA(一个具有挑战性的多语言基准测试)上,CANINE比mBERT模型的F1表现更好(尽管模型参数比mBERT模型少28%)。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢