
Facebook AI 提出新型视频理解架构:完全基于Transformer,无需卷积,训练速度快、计算成本低。TimeSformer 是首个完全基于 Transformer 的视频架构。近年来,Transformer 已成为自然语言处理(NLP)领域中许多应用的主导方法,包括机器翻译、通用语言理解等。
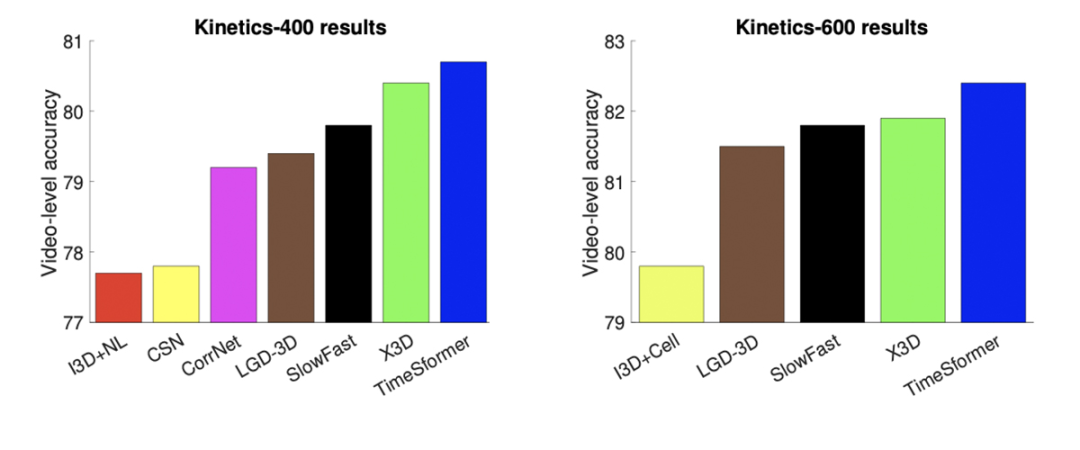
TimeSformer 在一些具有挑战性的动作识别基准(包括 Kinetics-400 动作识别数据集)上实现了最佳的性能。此外,与 3D 卷积神经网络(CNN)相比,TimeSformer 的训练速度大约是其 4 倍,而推断所需的计算量不足其十分之一。
- 论文名称:Is Space-Time Attention All You Need For Video Understanding?
- 论文链接:https://arxiv.org/pdf/2102.05095.pdf
更多详情可以戳原文。
来源:机器之心
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢