
作者 | 小O妹 来源 | Tengine开发者社区
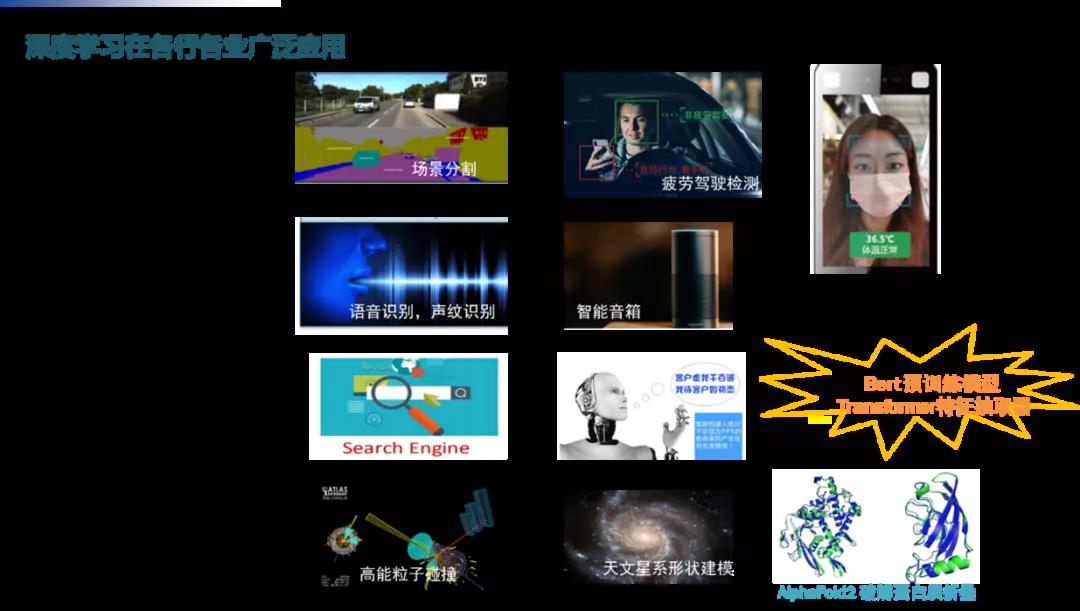
近年来,以机器学习、深度学习为核心的AI技术得到迅猛发展,深度神经网络在各行各业得到广泛应用:
CV(计算机视觉):目标检测,场景识别,图像分割等。
智慧语音:语音识别,声纹识别等。
NLP(自然语言处理):自动搜索引擎,对话服务机器人,文本分类,智能翻译等。
科学研究:应用于物理、生物、医学等多研究领域。高能粒子对撞分类,宇宙天体图数据分析,星系形状建模,生物结构的蛋白质折叠预测,精准医疗与疾病预测。
这些应用催生更多的新模型出现:CNN, RNN, LSTM, GAN, GNN,也催生着如Tensorflow, Pytorch, Mxnet, Caffe等深度学习框架出现。目前训练框架开始收敛,逐步形成了PyTorch引领学术界,TensorFlow主导工业界的一个双雄局面。
但是,深度学习算法要实现落地应用,必须被部署到硬件上,例如Google的TPU、华为麒麟NPU,以及其他在FPGA上的架构创新。

这些各训练框架训练出来的模型要如何部署到不同的终端硬件呢,这就需要深度学习神经网络编译器来解决。
在神经网络编译器出现之前,我们使用的是传统编译器。
下面是文章的主要内容,感兴趣可以戳原文了解:
传统编译器和神经网络编译器 TVM的前世今生 Halide AutoKernel
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢