
【标题】Solving Compositional Reinforcement Learning Problems via Task Reduction
【作者团队】Yunfei Li, Yilin Wu, Huazhe Xu, Xiaolong Wang, Yi Wu
【机构】清华大学&上海期智研究院
【原文链接】论文链接
【代码链接】代码链接
【发表时间】2021.3.13
【推荐理由】本文来源于清华大学和上海期智研究院团队联合,其提出了一种新颖的学习范式SIR,通过任务缩减和自我模仿来改善各种组合结构的稀疏奖励连续控制(组合RL)问题。
本文提出了一种新的学习范式,通过简化的自我模仿(SIR)来解决组合强化学习问题。SIR基于两个核心思想:任务缩减和自我模仿。
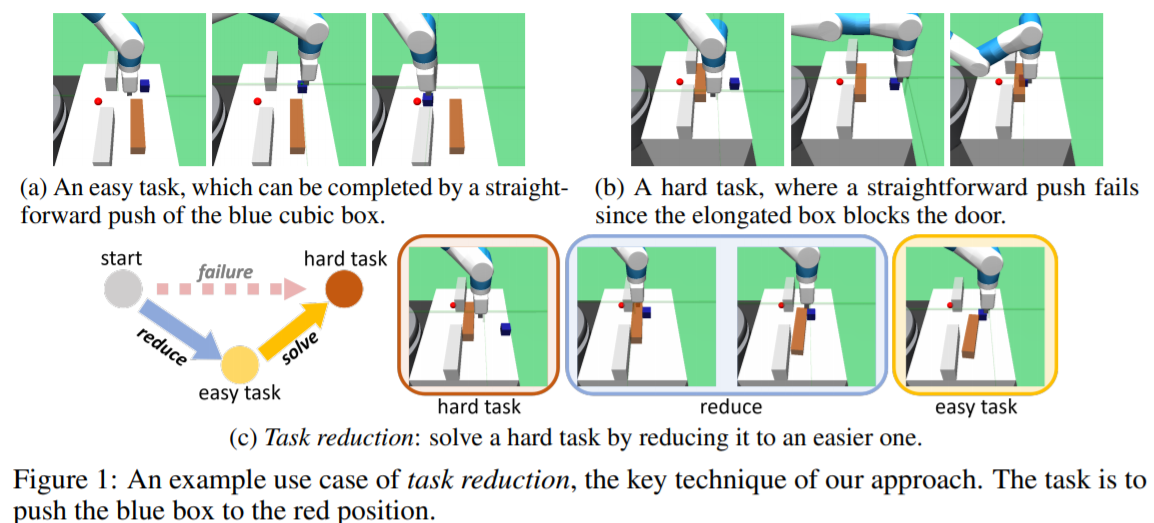 图1:任务减少
任务减少通过主动将一个难以解决的任务约简为一个更简单的任务来解决它,该任务的解被RL代理所知。一旦原始的艰巨任务通过任务减少成功求解,agent自然获得一条自生成的求解轨迹并进行模仿。通过不断收集和模仿这样的演示,代理能够在整个任务空间中逐步扩展已求解的子空间。实验结果表明,该算法能够显著加速和改善具有组合结构的各种具有挑战性的稀疏奖励连续控制问题的学习。
图1:任务减少
任务减少通过主动将一个难以解决的任务约简为一个更简单的任务来解决它,该任务的解被RL代理所知。一旦原始的艰巨任务通过任务减少成功求解,agent自然获得一条自生成的求解轨迹并进行模仿。通过不断收集和模仿这样的演示,代理能够在整个任务空间中逐步扩展已求解的子空间。实验结果表明,该算法能够显著加速和改善具有组合结构的各种具有挑战性的稀疏奖励连续控制问题的学习。
 图2:SIR算法
图2:SIR算法
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢