
【论文标题】Space-Time Crop & Attend: Improving Cross-modal Video Representation Learning 【作者团队】Mandela Patrick,Bernie Huang,Ishan Misra,Florian Metze,Andrea Vedaldi 【发表时间】2021/03/18 【机构】Facebook AI 实验室、牛津大学 【论文链接】https://arxiv.org/abs/2103.10211 【推荐理由】 本文出自 Facebook AI 实验室和牛津大学联合团队,作者提出了一种高效的时空裁剪&注意力(STiCA)模型,基于「特征裁剪」方法和 Transformer 模型高效地将静态图像中的裁剪等空间数据增强方式引入了视频表征学习领域,在多个对比基准上取得了目前最先进的性能。
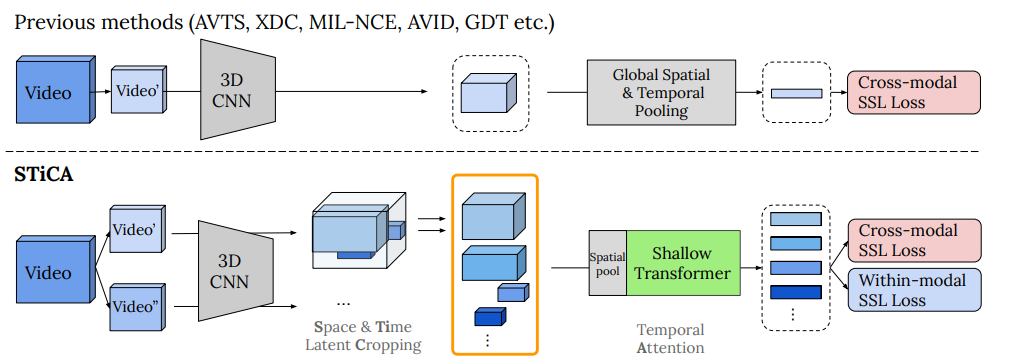
通过自监督学习学到的图像表征的质量在很大程度上依赖于学习过程中使用的数据增强方法。近年来,一些研究工作试图将这些方法从静态图像移植到视频中。他们发现,利用音频和视频信号会可以带来很大的性能提升。然而,他们并没有发现「裁剪」等对静态图像非常重要的空间数据增强方法也适用于视频。在本文中,作者以两种独特的方式在视频的时空层面上对这些学习方式进行了改进。 首先,在空间层面上,作者说明裁剪等空间增强方式在视频中也很有效。但是由于高昂的计算和存储开销,之前的实现方式不能完成大规模的工作。为了解决这个问题,作者首先引入了「特征裁剪」方法,这是一种直接在特征空间中更有效地模拟这种增强的方法。 第二,作者表明,与朴素的平均池化相比,使用基于 transformer 的注意力可以显著提高模型性能,并且非常适合特征裁剪操作。在本文中,作者将上述两项发现结合成了一种新的方法:时空裁剪&注意(STiCA)。 作者在多个视频表征学习对比基准上取得了目前最先进的性能。具体而言,作者在对 Kinetics-400 进行预训练的情况下,在 HMDB-51 上取得了 67.0% 的准确率,在 UCF-101 上取得了 93.1% 的准确率。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢