
在训练图像识别模型时,通过随机裁剪原始图像来增强数据做法并不少见。但是,如果一个图像包含多个对象,裁剪后的版本可能就不再匹配它的标签了。研究人员开发了一种方法来确保随机产物也能被准确标记。
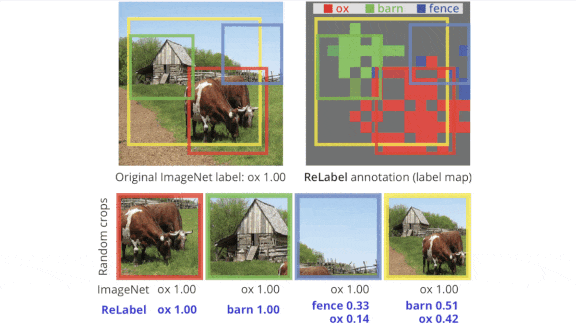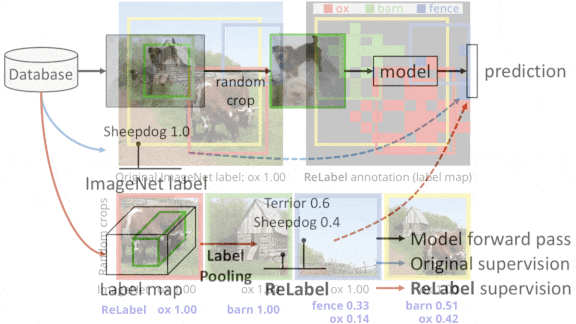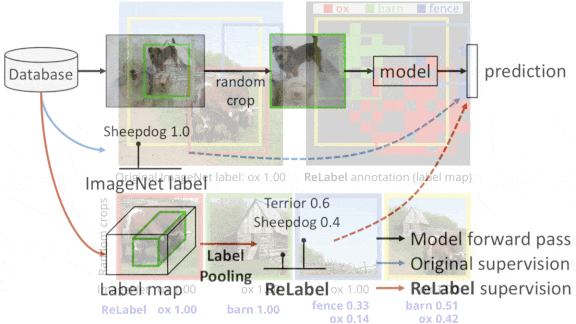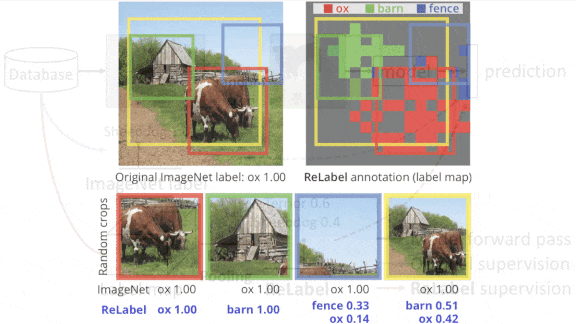 ●最新消息:在Sangdoo Yunn的领导下,Naver人工智能实验室的一个团队开发了ReLabel,这是一种可以对任何图像的任何随机裁剪进行标记的技术。他们用ImageNet展示了该方法。
●关键洞见:早期的研究使用了知识蒸馏:给定一个随机裁剪的图像,一个所谓的学生模型会从教师模型预测的标签上学习。这种方法要求教师模型为给定样本的每个裁剪版本预测一个标签。在这项工作中,一幅图像被划分成一个网格,教师模型为每个网格预测一个标签,并创建一个区域地图,它们的标签将用于确定图像中任何给定部分的标签。这样,教师模型就可以对每个样本检查一次,使整个过程更加有效。
●工作原理:教师模型是一个EfficientNet-L2,它已经在谷歌的JFT-3M数据集上进行了预训练。学生模型则是ResNet-50。
✴研究人员去掉了教师模型的最终池化层,这样网络就可以预测出15×15网格中每个区域的标签,而不是针对整个图像的一个标签。他们让教师模型预测ImageNet中每一张图像的“标签地图”。
✴研究人员使用ImageNet中的随机图像和相应的标签地图来训练学生模型。给定一个裁剪过的图像,他们使用RoIAlign在标签地图中找到与裁剪过的图像一致的区域,并将相应的区域汇集到一个向量中。然后使用softmax将向量转化为标签的概率分布。
●结果:研究人员比较了在ImageNet上使用标签训练的ResNet-50和使用标准标签训练的ResNet-50。新标签将测试分类准确率从77.5%提高到78.9%。
●为什么重要:社交和照片分享网站上的图片往往会被贴上标签,如果标签上写着“ox”,就表示图片上的某处有一头公牛。这种方法可以使视觉模型更好地利用社交网站这样的数据源。
●我们在想:在每个感兴趣的对象周围设置一个边界框可以改善裁剪问题,但这样的标签并不总是容易得到。
●最新消息:在Sangdoo Yunn的领导下,Naver人工智能实验室的一个团队开发了ReLabel,这是一种可以对任何图像的任何随机裁剪进行标记的技术。他们用ImageNet展示了该方法。
●关键洞见:早期的研究使用了知识蒸馏:给定一个随机裁剪的图像,一个所谓的学生模型会从教师模型预测的标签上学习。这种方法要求教师模型为给定样本的每个裁剪版本预测一个标签。在这项工作中,一幅图像被划分成一个网格,教师模型为每个网格预测一个标签,并创建一个区域地图,它们的标签将用于确定图像中任何给定部分的标签。这样,教师模型就可以对每个样本检查一次,使整个过程更加有效。
●工作原理:教师模型是一个EfficientNet-L2,它已经在谷歌的JFT-3M数据集上进行了预训练。学生模型则是ResNet-50。
✴研究人员去掉了教师模型的最终池化层,这样网络就可以预测出15×15网格中每个区域的标签,而不是针对整个图像的一个标签。他们让教师模型预测ImageNet中每一张图像的“标签地图”。
✴研究人员使用ImageNet中的随机图像和相应的标签地图来训练学生模型。给定一个裁剪过的图像,他们使用RoIAlign在标签地图中找到与裁剪过的图像一致的区域,并将相应的区域汇集到一个向量中。然后使用softmax将向量转化为标签的概率分布。
●结果:研究人员比较了在ImageNet上使用标签训练的ResNet-50和使用标准标签训练的ResNet-50。新标签将测试分类准确率从77.5%提高到78.9%。
●为什么重要:社交和照片分享网站上的图片往往会被贴上标签,如果标签上写着“ox”,就表示图片上的某处有一头公牛。这种方法可以使视觉模型更好地利用社交网站这样的数据源。
●我们在想:在每个感兴趣的对象周围设置一个边界框可以改善裁剪问题,但这样的标签并不总是容易得到。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢