
【论文标题】DeepViT: Towards Deeper Vision Transformer 【作者团队】D Zhou, B Kang, X Jin, L Yang, X Lian, Q Hou, J Feng 【发表时间】2021/03/23 【机 构】新加坡国立大学&字节跳动 【论文链接】https://arxiv.org/pdf/2103.11886.pdf 【代码链接】https://github.com/zhoudaquan/dvit_iccv21 【推荐理由】本文来自新加坡国立大学。文章深入研究了视觉Transformer的行为,并提出Re-attention,一个简单而有效的注意力机制用于视觉Transformer。
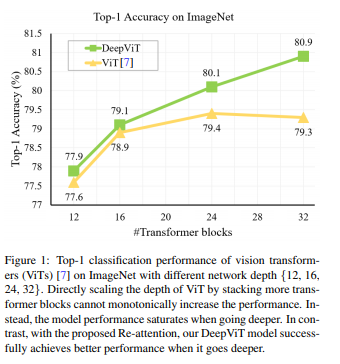
近年来,视觉Transformer(ViTs)在图像分类中得到了成功的应用。本文深入研究了视觉Transformer的行为,观察到它们不能像CNN那样不断地从堆叠更多的层数中获益。进一步找出这种反直觉现象背后的根本原因,将其总结为注意力坍缩:随Transformer深度加大,注意力图在一定层数后逐渐变得相似,甚至雷同。在更深的视觉Transformer中,自注意力机制无法学习到有效的概念进行表征学习,阻碍了模型获得预期的性能提升。提出Re-attention,一个简单而有效的注意力机制,考虑了不同注意头之间的信息交换,以重新生成注意力图,增加其在不同层的多样性,而计算和内存成本可以忽略。所提出方法通过对现有的视觉Transformer模型进行微小修改,使得训练更深层的视觉Transformer成为可行的,性能也得到了持续的提升。当训练具有32个Transformer块的深度视觉Transformer模型时,在ImageNet上Top-1分类精度可以提高1.6%。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢