
论文标题:Multi-view 3D Reconstruction with Transformer 论文链接:https://arxiv.org/abs/2103.12957 作者单位:UBC & 中科大 密歇根大学, 网易
3D Volume Transformer(VolT)表现SOTA!性能优于Pix2Vox、AttSets等网络,代码即将开源!
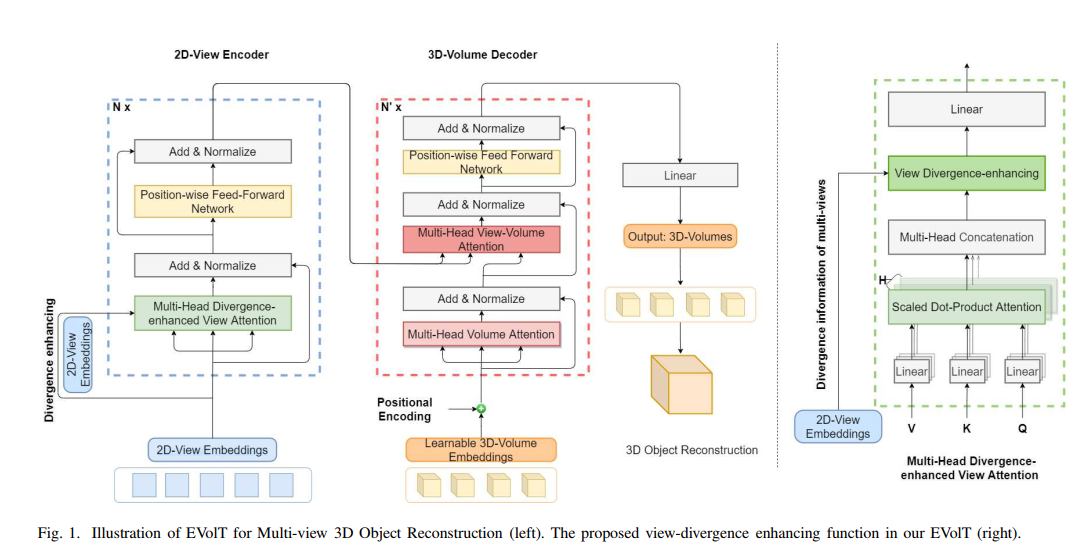
迄今为止,基于深度CNN的方法已实现了多视图3D物体重建的最新技术成果。尽管取得了长足的进步,但是这些方法的两个核心模块(多视图特征提取和融合)通常是分别研究的,很少探讨不同视图中的对象关系。在本文中,受基于自注意力的Transformer模型最近取得的巨大成功的启发,我们将多视图3D重构重新设计为序列到序列的预测问题,并为此提出了一个名为3D Volume Transformer(VolT)的新框架。一个任务。与以前使用单独设计的基于CNN的方法不同,我们在单个Transformer网络中统一特征提取和视图融合。我们设计的自然优势在于使用多个无序输入之间的自注意力来探索视图与视图之间的关系。在ShapeNet(大型3D重建基准数据集)上,我们的方法比其他基于CNN的方法以更少的参数(少了70%)实现了多视图重建中最新的最新精度。实验结果也表明我们的方法具有很强的缩放能力。我们的代码将公开提供。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢