
【论文标题】Vision Transformers for Dense Prediction 【作者团队】Rene Ranftl,Alexey Bochkovskiy,Vladlen Koltun 【发表时间】2021/03/24 【机构】英特尔实验室 【论文链接】https://arxiv.org/pdf/2103.13413.pdf 【代码链接】https://github.com/intel-isl/DPT
【推荐理由】 本文出自英特尔实验室,作者提出了一种在各个尺度上构建 Transformer 视觉表征的密集视觉 Transformer 模型,该模型相较于全卷积网络可以得到粒度更细、更具有全局一致性的密集预测结果,在多个数据集上表现 SOTA。
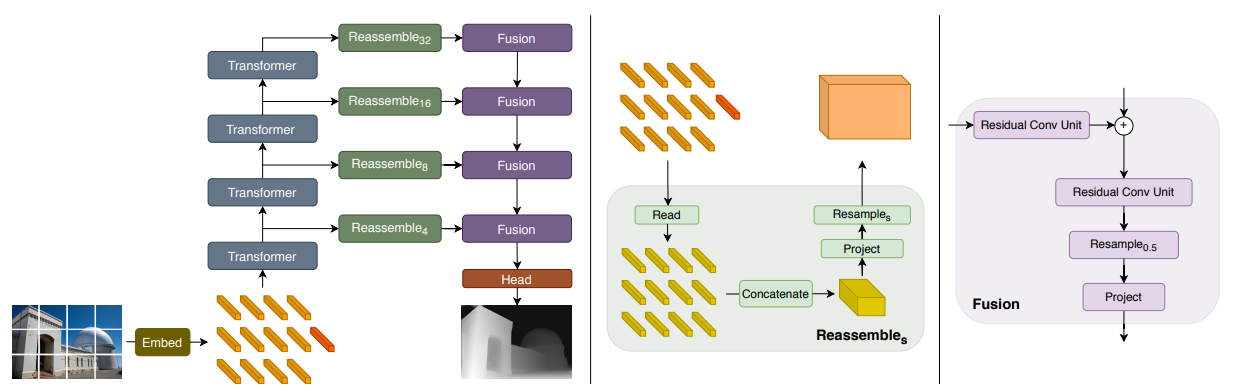
在本文中,作者提出了一种密集视觉 Transformer,这是一种利用视觉 Transformer 在密集预测任务中用作替代卷积网络的主干网络的架构。本文作者将视觉 Transformer 各阶段中的 token 集成到了各种分辨率下的类似于图像的表征中,并且使用一个卷积解码器逐渐的将它们融合到全分辨率预测中。 Transformer 主干网络以恒定且较高的分辨率处理上述表征,并且在每个阶段都拥有全局感受野。这种特性使得密集视觉 Transformer 可以得到细粒度,并且比全卷积网络更加全局一致的预测结果。 本文作者通过实验说明,该架构在密集预测任务上取得了实质性的改进(尤其是在有大量训练数据的情况下)。在单目深度估计任务中,本文提出的框架相较于当前最优的全卷积网络取得了高达 28% 相对性能的提升。作者将密集视觉 Transformer 应用于语义分割任务上时,该框架在 ADE20K 数据集上取得了目前最优的性能,其 mIOU 为 49.02%。此外,作者还说明该架构可以 NYUv2、KITTI、Pascal Context 等小型数据集上进行调优,并且仍可以取得最优的性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢