
【标题】Reward-Reinforced Reinforcement Learning for Multi-agent Systems 【作者团队】Changgang Zheng, Shufan Yang, Juan Parra-Ullauri, Antonio Garcia-Dominguez, Nelly Bencomo 【研究机构】牛津大学&爱丁堡龙比亚大学 【发表时间】2021.3.21 【论文链接】原文链接 【推荐理由】本文提出了一种基于奖励增强GAN(RR-GAN)的多智能体系统通用框架,该框架有可能推广到任何多智能体系统。 其使用生成器网络作为用户分布的隐式指示,以实现协作多智能体系统的全局目标最大化。
多智能体系统为电信、航空航天和工业机器人领域的常见问题提供了高度灵活且适应性强的解决方案。然而,对于协作多智能体系统来说,实现一个最优的全局目标仍然是一个持续的障碍,其学习会影响多个智能体的行为。为了解决Bellman方程,提出了许多非线性函数逼近方法,这些方法描述了最优策略的递归格式。然而,如何利用基于强化学习的价值分配,以及如何提高这种系统的效率和功效仍然是一个挑战。本文开发了一个奖励增强的生成对抗网络来表示价值函数的分布,从而替代了Bellman更新的近似值。本文证明了该方法是有弹性的,并且优于其他传统的强化学习方法。此方法也适用于实际的案例研究:最大化移动通信网络中与自治机载基站的用户连接数量。该方法使用成本函数使代理具有最佳的学习行为,从而最大程度地提高了数据的可能性。这种奖励增强的生成对抗网络可以用作为系统层面多主智能体学习的通用框架。
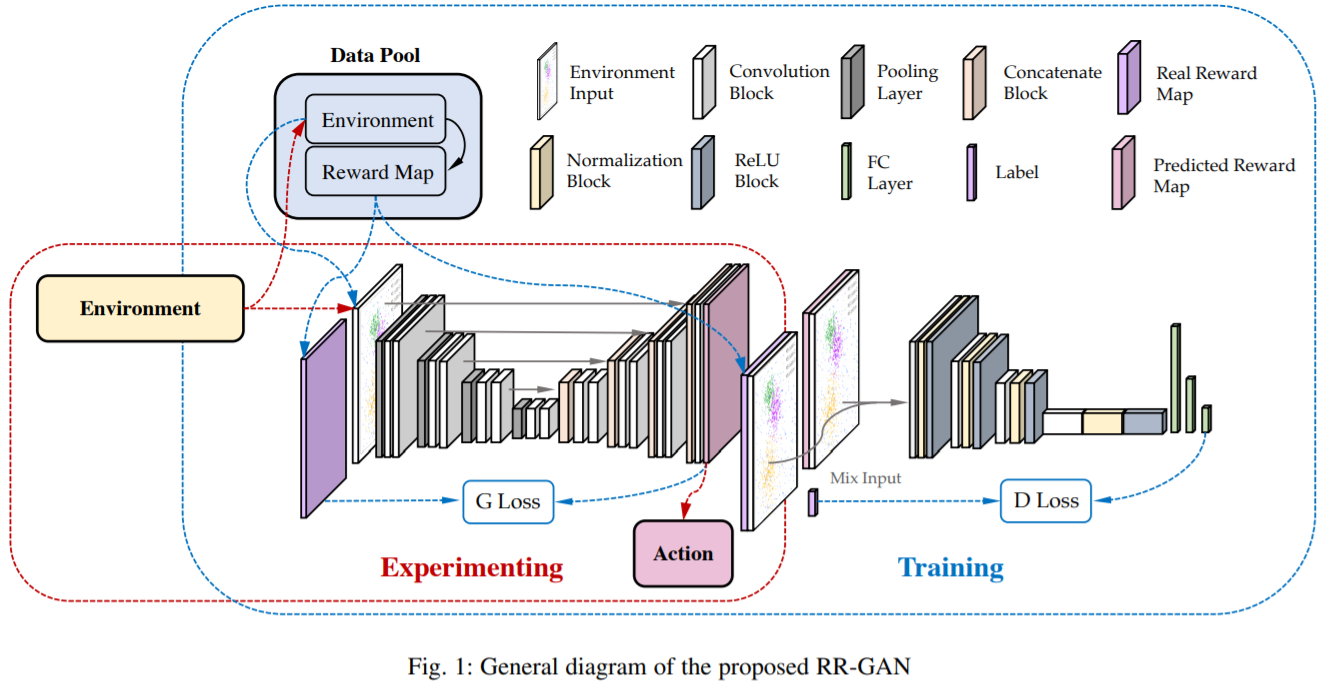 图1:通用RR-GAN框架
图1:通用RR-GAN框架
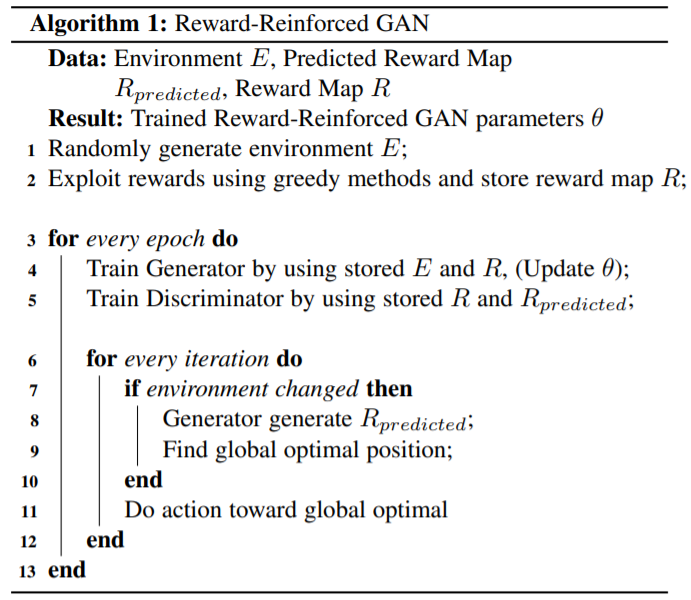 图2: RR-GAN的伪代码
图2: RR-GAN的伪代码
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢