
【标题】The Gradient Convergence Bound of Federated Multi-Agent Reinforcement Learning with Efficient Communication 【作者团队】Xing Xu, Rongpeng Li, Zhifeng Zhao, Honggang Zhang 【研究机构】浙大 【发表时间】2021.3.24 【论文链接】原文链接 【推荐理由】本文为了分析FMARL范式下策略迭代解的收敛边界,利用SGD的优势和联合学习的特点对随机策略梯度过程进行了优化。此外,为了提高系统的效用值,本文在变异感知周期平均法的基础上提出了两种新的优化方法。通过对理论收敛范围的分析和大量仿真,验证了所提出方法的有效性和高效性。
本文考虑了联合学习范式中用于多智能体决策过程的深度强化学习(DRL)的分布式版本。由于联合学习中的深度神经网络模型是在本地进行训练的,并且通过中央服务器进行迭代地聚合,因此频繁的信息交换会导致大量的通信开销。此外,由于智能体的异质性,来自不同智能体的马尔可夫状态转移轨迹通常在同一时间间隔内是不同步的,这将进一步影响聚集的深度神经网络模型的收敛范围。因此,合理评估不同优化方法的有效性至关重要。基于此,本文提出一种效用函数,以考虑减少通信开销和提高收敛性能之间的平衡。同时,本文在变异感知周期平均方法的基础上开发了两种新的优化方法:1)基于衰减的方法,在局部更新的过程中逐渐减小模型局部梯度的权重; 2)基于共识的方法该方法将共识算法引入了联和学习中,以交换模型的局部梯度。本文还为两种已开发方法提供了新颖的收敛性保证,并通过理论分析和数值模拟结果证明了该方法的有效性和效率。
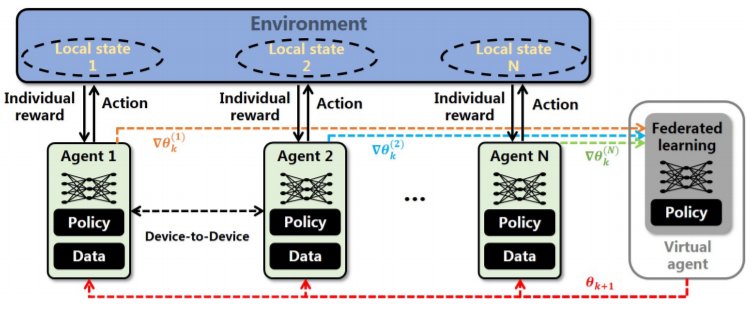 图1:FMARL框架
图1:FMARL框架
 图2:FMARL训练算法
图2:FMARL训练算法
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢