
【论文标题】Model Predictive Actor-Critic: Accelerating Robot Skill Acquisition with Deep Reinforcement Learning
【作者团队】Andrew S. Morgan, Daljeet Nandha, Georgia Chalvatzaki, Carlo D'Eramo, Aaron M. Dollar, Jan Peters
【发表时间】2021.03.25
【论文链接】https://arxiv.org/abs/2103.13842
【代码链接】https://github.com/dnandha/mopac
【推荐理由】
受信息理论模型预测控制和深度强化学习进展的启发,作者提出了模型预测行为-批评机制(MoPAC),这是一种基于模型/免模型的混合方法,将模型预测推出与策略优化相结合,从而减轻模型偏差。
基于模型的强化学习算法实质性进步已受到所收集数据引起的模型偏差的阻碍,这通常会损害性能。同时,它们固有的样品效率保证了其在大多数机器人应用中的实用性,从而限制了训练期间对机器人及其环境的潜在损害。MoPAC利用最佳轨迹来指导策略学习,但通过其无模型方法进行探索,从而使该算法可以学习更具表现力的动力学模型。这种结合保证了最佳技能的学习,直至接近误差,并减少了与环境的必要物理交互,使其适合于实际的机器人训练。
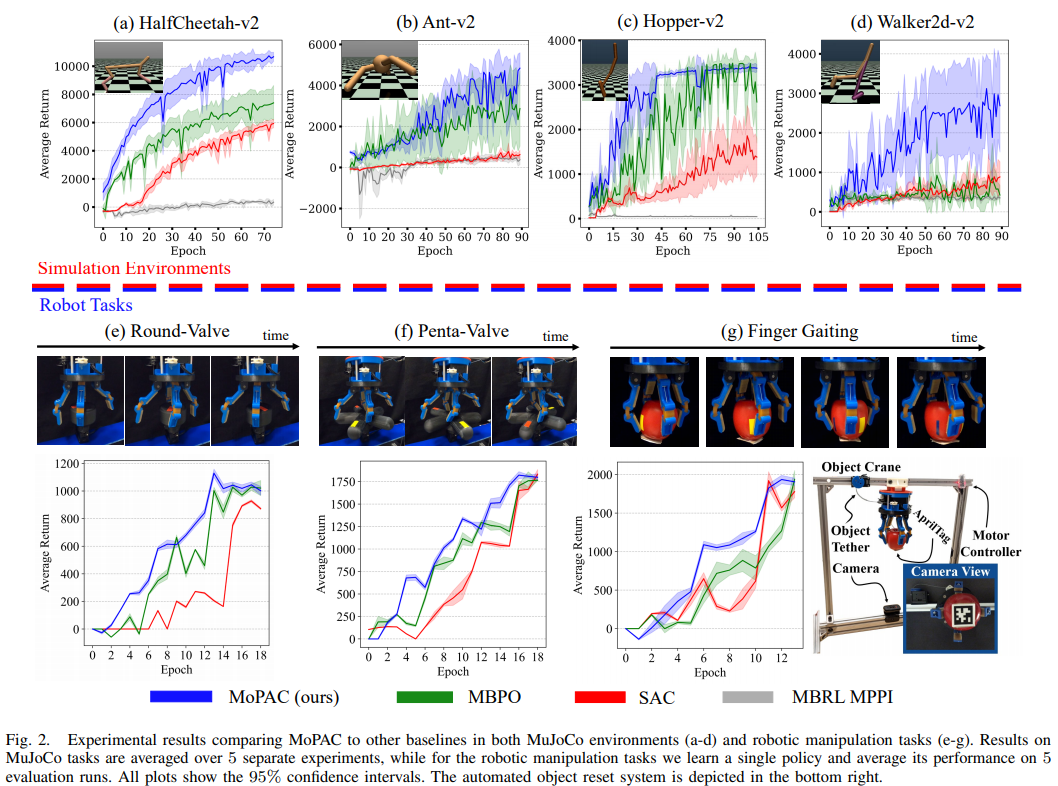 在这项工作中,作者提出了模型预测机制(MoPAC),一种试图结合深MF演员评论家方法的优点和MB方法的数据效率的方法。特别是,MoPAC引入了模型预测展开,其灵感来自于信息论模型预测路径积分,基于动力学自由能原理和通过轨迹优化收集样本的信息论约束。MoPAC使用MFRL-actor-critic算法进行策略改进和模型学习,并使用模型进行模型预测,以收集额外的样本来指导策略学习。MoPAC的核心优势在于,虽然MB的推出有利于通过使用模型进行规划来开发策略,但MFRL actor-critic鼓励对策略优化和模型学习进行有效的探索。
在这项工作中,作者提出了模型预测机制(MoPAC),一种试图结合深MF演员评论家方法的优点和MB方法的数据效率的方法。特别是,MoPAC引入了模型预测展开,其灵感来自于信息论模型预测路径积分,基于动力学自由能原理和通过轨迹优化收集样本的信息论约束。MoPAC使用MFRL-actor-critic算法进行策略改进和模型学习,并使用模型进行模型预测,以收集额外的样本来指导策略学习。MoPAC的核心优势在于,虽然MB的推出有利于通过使用模型进行规划来开发策略,但MFRL actor-critic鼓励对策略优化和模型学习进行有效的探索。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢