
【论文标题】SimPLE: Similar Pseudo Label Exploitation for Semi-Supervised Classification
【作者团队】Zijian Hu,Zhengyu Yang,Xuefeng Hu,Ram Nevatia
【发表时间】2021/03/30
【机 构】南加州大学
【论文链接】https://arxiv.org/pdf/2103.16725.pdf
【代码链接】https://github.com/zijian-hu/SimPLE
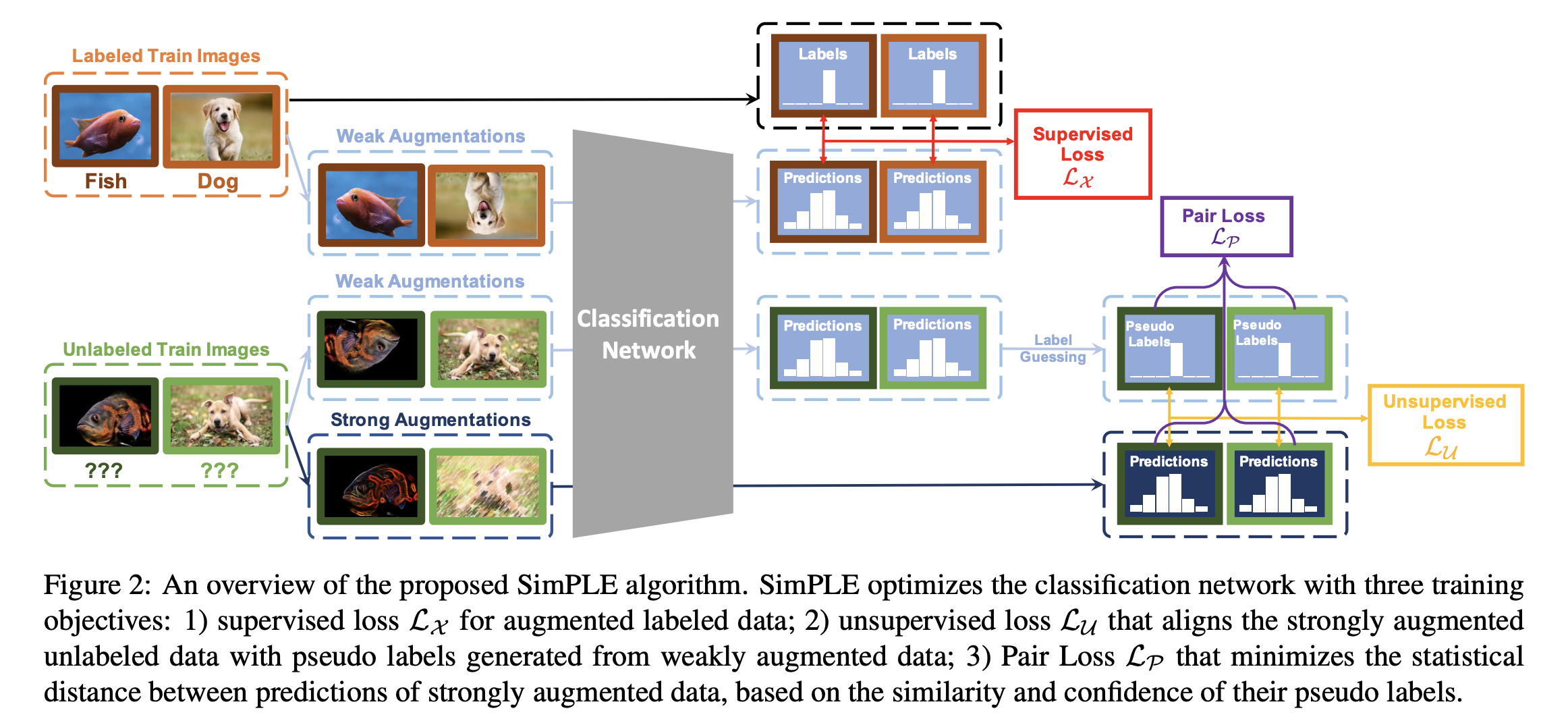
【推荐理由】本文来自南加州大学,已被CVPR2021接收。文章提出了一个新颖的目标损失用于半监督学习,可以使得相似度超过一定阈值的高置信度伪标签之间的统计距离最小。
一种常见的分类任务情况是,有大量数据可用于训练,但只有一小部分数据带有标签标注的。在这种情况下,半监督训练的目标是通过利用标记数据和大量未标记数据的信息来提高分类精度。最近的工作通过探索不同增强标记和未标记数据之间的一致性约束,取得了显著的改进。基于此,本文提出了一个新的无监督目标,重点放在研究较少的高置信度无标记数据之间的关系是相似的。新的Pair-loss算法使得相似度高于某一阈值的高置信度伪标签之间的统计距离最小。实验证明,本文提出的SimPLE算法相比基准算法,取得了显著的提升。此外,SimPLE在迁移学习环境中也取得了SOTA的结果。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢