
论文标题:Robust Facial Expression Recognition with Convolutional Visual Transformers 论文链接:https://arxiv.org/abs/2103.16854 作者单位:湖南大学(李树涛团队)
据作者称,这是第一个将Transformer应用于人脸表情识别(FER)的工作!表现SOTA!性能优于SCN、RAN、SPWFA-SE等网络。
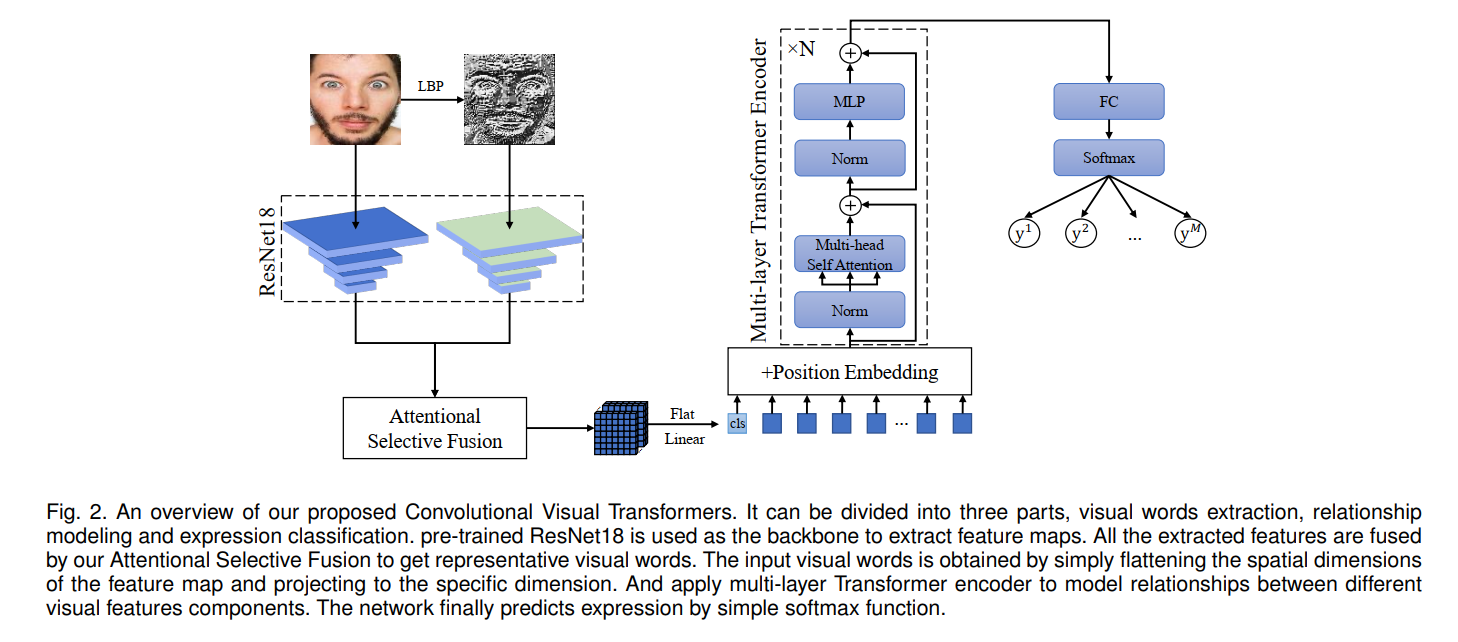
人脸表情识别(FER)in the wild极具挑战性,原因是在不受限制的条件下,遮挡,头部姿势变化,人脸变形和运动模糊。尽管在过去的几十年中,自动FER取得了实质性进展,但以前的研究主要是针对实验室控制的FER设计的。由于这些信息不足的区域和复杂的背景,现实世界中的遮挡,头部姿势变化和其他问题无疑增加了FER的难度。与以前的基于纯CNN的方法不同,我们认为将人脸图像转换为视觉单词序列并从全局角度执行表情识别是可行和实际的。因此,我们提出了卷积视觉Transformer,通过两个主要步骤来解决in the wild中的FER。首先,我们提出一种注意选择性融合(ASF),以利用两分支CNN生成的特征图。 ASF通过将多个功能与全局注意力的特征融合在一起来捕获区分性信息。然后将融合的特征图展平并投影到视觉单词序列中。其次,受Transformer在自然语言处理中成功的启发,我们提出对具有全局自注意力的这些视觉单词之间的关系进行建模。对三个公开的in-the-wild人脸表情数据集(RAF-DB,FERPlus和AffectNet)进行了评估。在相同的设置下,广泛的实验表明我们的方法显示出优于其他方法的性能,在RAF-DB上以88.14%,FERPlus在88.81%和AffectNet在61.85%上设置了新的技术水平。我们还对CK +进行了跨数据集评估,显示了该方法的泛化能力。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢