
【论文标题】UC2: Universal Cross-lingual Cross-modal Vision-and-Language Pre-training 【作者团队】Mingyang Zhou, Luowei Zhou, Shuohang Wang, Yu Cheng, Linjie Li, Zhou Yu, Jingjing Liu 【发表时间】2021/03/30 【机构】加州大学戴维斯分校、微软 Dynamics 365 人工智能研究院 【论文链接】https://arxiv.org/pdf/2104.00332.pdf 【推荐理由】 本文出自加州大学戴维斯分校和微软联合团队,作者提出了一种新的跨语言、跨模态预训练框架 UC^2,该框架基于机器翻译技术构建了用于多语言、多模态预训练的新数据集,并设计了两种新的预训练任务提升联合嵌入学习的性能,该框架在多个对比基准测试上获得了 SOTA 的性能。
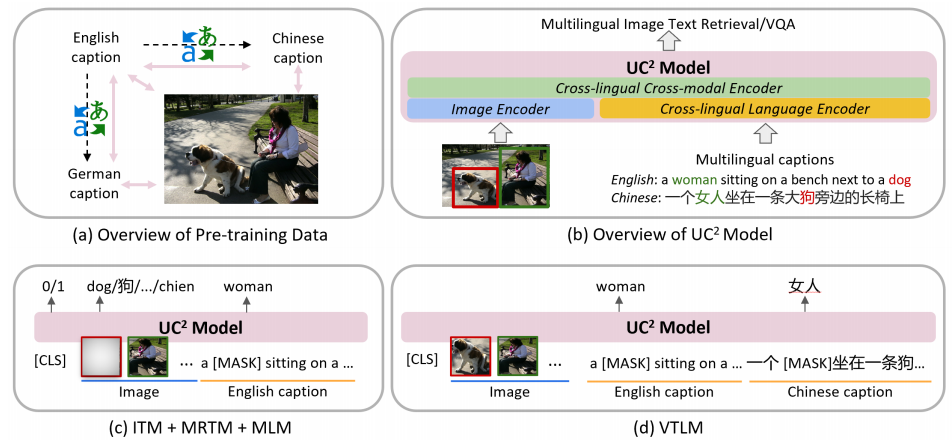
「视觉-语言」预训练在学习视觉和语言之间的多模态表征任务中取得了巨大的成功。为了将这一成功泛化到非英语的环境下,本文作者则提出了 UC^2,这是首个用于跨语言、跨模态表征学习的机器翻译增强框架。 为了解决缺乏多语言图像描述数据集的问题,本文作者首先通过机器翻译技术得到的其它语言增强了现有的英文数据集。接着,作者对标准的掩模语言建模和「图像-文本」匹配训练目标函数拓展到了多语言环境下,通过共享视觉上下文(即以图像为中心)实现了不同语言之间的对齐。为了促进对图像和所有感兴趣的语言的联合嵌入的学习,本文作者进一步利用基于机器翻译增强的翻译数据提出了两种新的预训练任务:Masked Region-to-Token Modeling (MRTM) 和 Visual Translation Language Modeling (VTLM)。作者通过在「图像-文本」检索和多语言视觉问答对比基准上的实验说明了本文提出的方法在多个非英语对比基准上取得了目前最先进的性能,同时在英语任务上保持了与单语言预训练模型相当的性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢