
【标题】Multi-Agent Collaboration via Reward Attribution Decomposition
【作者团队】Tianjun Zhang, Huazhe Xu, Xiaolong Wang,Yi Wu, Kurt Keutzer, Joseph E. Gonzalez, Yuandong Tian
【研究机构】Facebook AI Research, UC Berkeley
【发表时间】2020.10
【论文链接】https://arxiv.org/pdf/2010.08531.pdf
【推荐理由】本文试图从第一性原理出发,思考多智能体协作应当如何建模。通过深入思考智能体间协作的意义,在每个智能体之所以会和别人协作,完全是因为委派的奖励不同的假设下提出了新的决定委派奖励的目标函数。在星际争霸任务中,胜率提升明显。
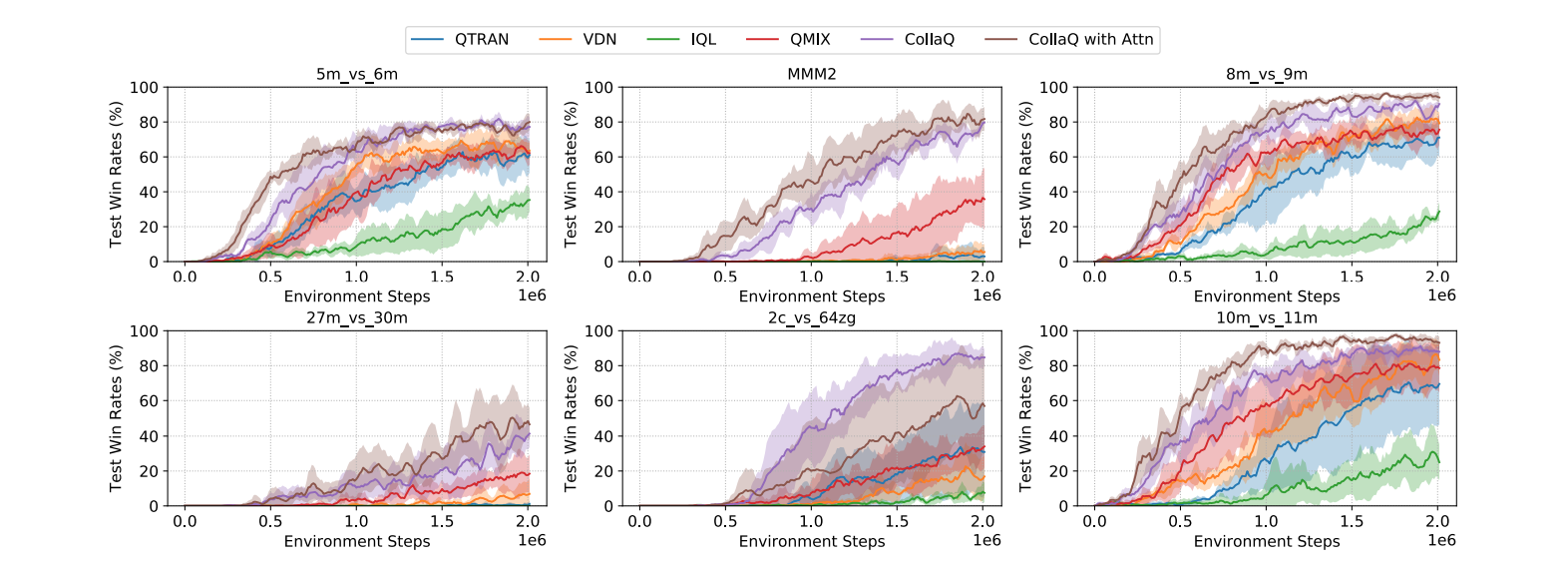
最近在多代理强化学习(MARL)方面的进展已经实现了在《Quake 3》和《Dota 2》等游戏中的超人表现。不幸的是,这些技术比人类需要更多数量级的训练轮次,而且可能会不能泛化到稍有改变的环境或新的智能体配置。在这项工作中,我们提出了协作式问答学习(CollaQ)。在《星际争霸》多智能体挑战赛中取得了最先进的性能。我们首先将多智能体协作表述为奖励分配上的联合优化,并表明在一定条件下。每个代理都有一个近似最优的分散的Q函数,可以是分解为两个项:只依靠智能体自身状态的自项和与附近智能体的状态有关的互动项。这两项采用带有能确保语义的多智能体奖励归属(MARA)损失正则项的常规联合DQN。CollaQ在各种星际争霸地图上进行了评估,表现优于现有的最先进的技术(即QMIX、QTRAN和VDN)。通过改进在环境步数相同的情况下,胜率提高40%。在更具有挑战性的临时团队游戏设置(即在替换/增加/减少单位的情况下,不重新训练或微调)。CollaQ的性能比以前的SoTA高出30%以上。
CollaQ和一些基线方法(如QMix,QTRAN,VDN,IDL等)的比较如下图所示。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢