
【标题】Domain Adaptation In Reinforcement Learning Via Latent Unified State Representation
【作者团队】Jinwei Xing, Takashi Nagata, Kexin Chen, Xinyun Zou, Emre Neftci, Jeffrey L. Krichmar
【研究机构】加州大学欧文分校
【发表时间】2021.2
【论文链接】https://arxiv.org/pdf/2102.05714.pdf
【推荐理由】本文收录于AAAI 2021,从强化学习泛化能力的角度展开研究。用状态表征的方法成功将任务相关和任务无关的状态从原始图像中解耦,使得已经训练好的模型能在不同场景中迁移。实验在CarRacing和CARLA中获得显著的效果。
尽管深度强化学习(DRL)最近获得了很大的成功,领域迁移还是一个开放问题。强化学习智能体的泛化能力对于深度强化学习在现实世界中的运用至关重要,然而zero-shot策略迁移是个极具挑战的问题,以至于图像上一个很小的变化就能使得训练好的智能体在新任务中运行失败。为了解决这个问题,我们提出了一个两阶段强化学习框架。智能体在第一阶段学习一个能在多领域具有一致性的隐统一状态表征(latent unified state representation LUSR)。第二阶段就是在源领域中基于LUSR做强化学习训练。LUSR在不同领域中的一致性使得可以在不用额外训练的情况下把从源领域中获得的策略泛化到其它目标领域中。我们首先在不同的CarRacing游戏中验证了我们的方法,然后在一个自动驾驶的模拟器CARLA中测试了我们的算法。我们的结果表明这个方法能达到SOTA的领域迁移效果,并且优于之前基于隐表示的强化学习算法和基于图像转换的方法。
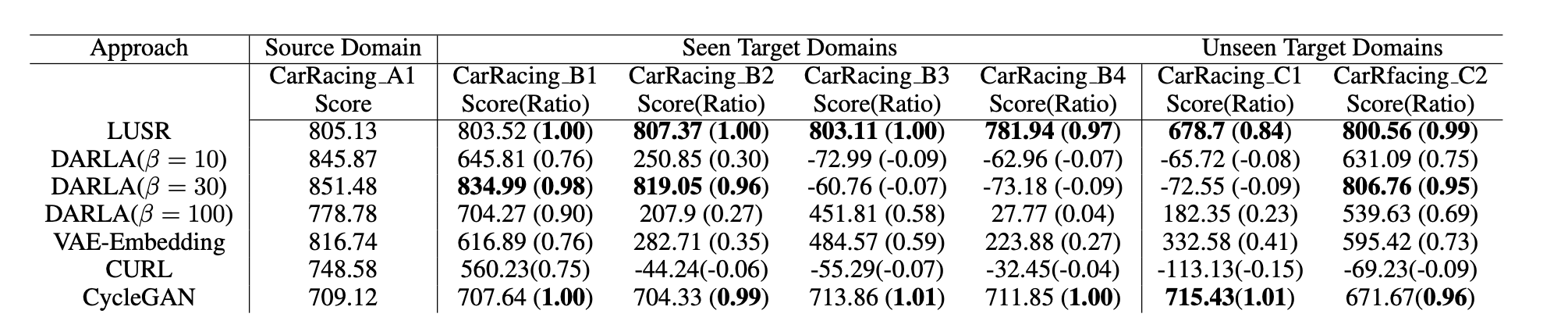 表1:LUSR在CarRacing中的效果
表1:LUSR在CarRacing中的效果
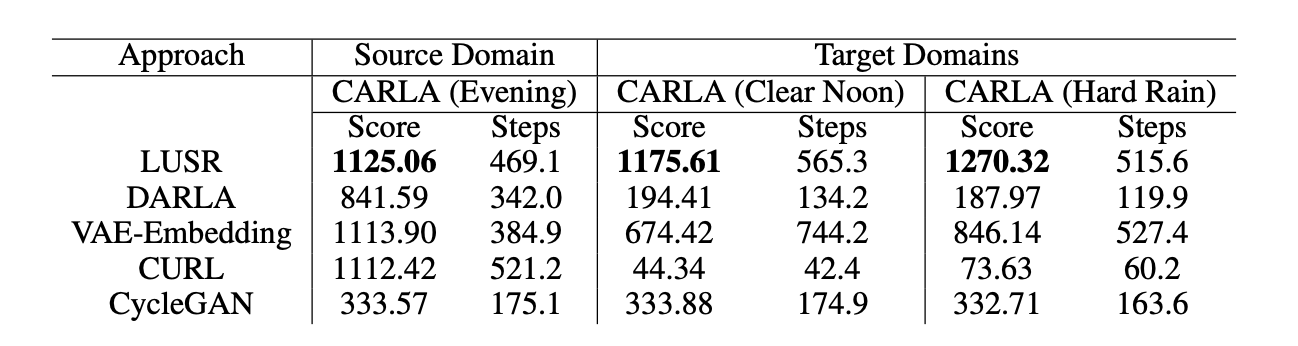 表2:LUSR在自动驾驶模拟器CARLA中的效果
表2:LUSR在自动驾驶模拟器CARLA中的效果
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢