
抗噪鲁棒性学习是机器学习中一个非常重要和热门的领域,各类方法也层出不穷。在本文中,来自香港浸会大学、清华大学等机构的研究者对标签噪声表征学习(LNRL)的方方面面进行了全方位的综述。
监督学习方法通常依赖精确的标注数据,然而在真实场景下数据误标注(标签噪声)问题不可避免。例如,对于数据本身存在不确定性的医疗任务,领域专家也无法给出完全可信的诊断结果;基于用户反馈的垃圾邮件过滤程序,用户作为标注人员存在行为的不确定性(例如误点击)。不论是从理论还是从实验角度,人们均发现常见的学习算法会受到标签噪声的负面影响,因此对标签噪声鲁棒的统计学习方法受到广泛的关注。
在大数据和深度学习的背景下,标签噪声的研究如今有更加重要的意义。一方面,过去基于统计一致性的方法在深度学习领域表现欠佳,而使用非专家提供的噪声标注(如众包平台)则是解决深度学习 data-hungry 问题的重要技术。另一方面,标签噪声对神经网络性能的影响反过来促进了深度学习的理论研究,加深人们对深度学习本质的理解。
深度学习框架下的标签噪声问题(Label Noise Representation Learning, LNRL)最近受到越来越多的关注。在 NeurIPS、ICML 等机器学习顶会中,LNRL 相关文章从 2015 年的 5 至 6 篇迅速增长到如今的几十篇。李飞飞、Yoshua Bengio 等著名学者均发表了大量相关文章。
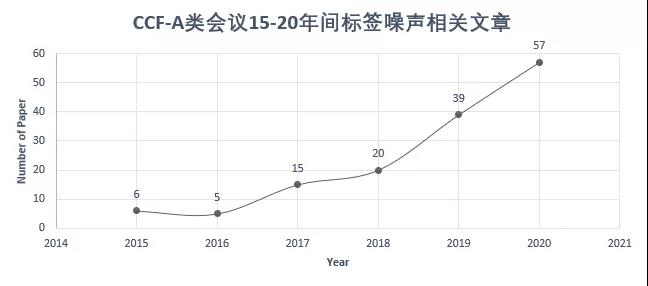
本文介绍了 LNRL 的最新综述论文《A Survey of Label-noise Representation Learning: Past, Present, and Future》,其中包含超百篇领域前沿文章。论文作者分别来自香港浸会大学、清华大学、香港科技大学、悉尼大学、悉尼科技大学、日本理化研究所和第四范式。
- 论文名称:A Survey of Label-noise Representation Learning: Past, Present and Future
- 论文地址:https://arxiv.org/abs/2011.04406
- Github 地址:https://github.com/bhanML/label-noise-papers
感兴趣的可以继续戳原文。
来源:机器之心
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢