
 要说自然语言处理领域当今最 fashion 的“神兵”,恐怕非预训练语言模型莫属。
要说自然语言处理领域当今最 fashion 的“神兵”,恐怕非预训练语言模型莫属。
2018年 BERT 横空出世,那真可谓是打开了 NLP 新世界的大门。
且在这条预训练+微调的修行之路上,各路高手那叫一个百花齐放,各领风骚。
你看 XLNet 才把 BERT 从榜单之巅拉下马,那厢 RoBERTa 便进一步“榨干”BERT 性能,重归榜首。 其实,还不仅仅是西方选手轮番登台,文心 ERNIE 等东方身影也不乏精彩表现。
那么,这两年多以来,都有哪些模型表现可圈可点? 今天,诸位看官便不妨随我盘点一番~ 且看 GLUE 兵器谱
如果把预训练语言模型都比喻成兵器,那江湖上自有“百晓生兵器谱”,能给它们排个一二三四五。
GLUE 就是自然语言处理领域的权威排行榜之一。
该榜单由纽约大学、华盛顿大学、DeepMind 等机构联合推出,一直以来被视作评估 NLP 研究进展的行业标准。

因此,这 GLUE 榜首之争,那真是相当的激烈。能够夺魁的“神兵”,自然也各有各的文章。
玄铁重剑 BERT
就说这 BERT,甫一亮相,就以预训练+微调的 2-Stage 模式,直接将 GLUE 基准拉高7.7%,端的是惊艳了众 NLP 开发者。

具体而言,BERT 是基于 Transformer 的深度双向语言表征模型。预训练模型只需要增加一个输出层就可以进行微调,从而适应更广泛的新任务。
这种概念上的简练,正可谓是重剑无锋,大巧不工。
鸳鸯剑 XLNet
BERT 虽好,但缺点也不是没有。比如预训练时的 MASK 标记在微调时并不会被看到,会产生忽略两个实体之间关联的情况,产生预训练-微调差异。
自回归模型可以避免这样的问题。于是,“鸳鸯剑”XLNet 就登场了——这是一个双向特征表示的自回归模型。
 并且,作为一个泛化自回归语言模型,XLNet 不依赖残缺数据。
并且,作为一个泛化自回归语言模型,XLNet 不依赖残缺数据。
倚天剑 RoBERTa
不过就在 XLNet“霸榜”一个月之后,BERT 的强势继承人就出现了。
Facebook 把 BERT 改进了一番,进一步“榨干”了BERT 的性能,以 RoBERTa 之名重回巅峰。那架势恰是“倚天一出,谁与争锋”。
简单来说,RoBERTa 主要做了这样的修改:更长的训练时间,更大的 batch,更多的数据……
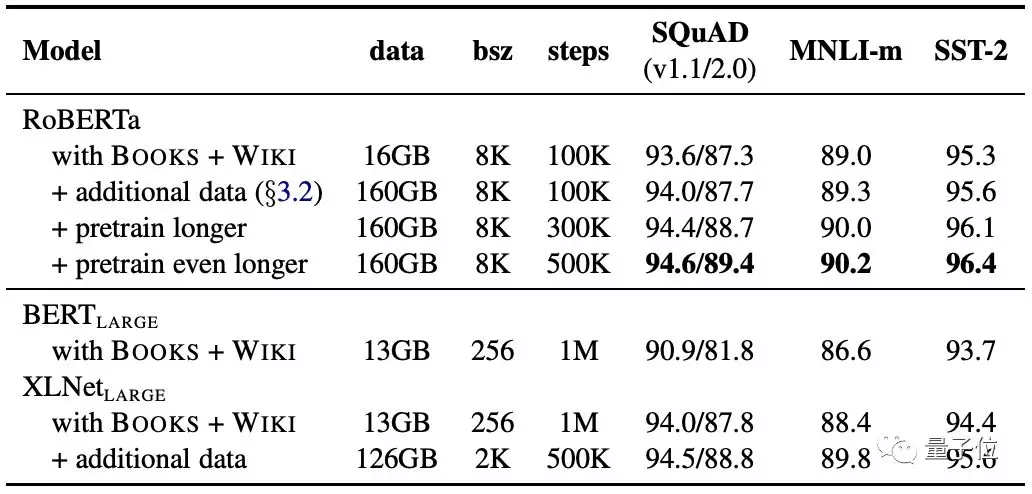
单从数据来看,原始的 BERT 使用了 13GB 大小的数据集,而 RoBERTa 使用了包含6300万条英文新闻的 160GB 数据集。
而在训练时间上,RoBERTa 需要使用1024个英伟达 V100 训练大约1天的时间。
说到这,诸位看官可能会问,那咱们国内的“兵器”们,可曾榜上留名,与这些西方名兵交映生辉啊?
答案是肯定的。
屠龙刀 文心 ERNIE
百度家大名“文心”的二妮(ERNIE),就在最近再夺榜首。

“屠龙宝刀”锋利之极,无坚不摧。而文心 ERNIE 的锋利之处,在于能融合大规模知识持续学习进化,久经打磨而其刃不卷。
这已经不是“国货之光”ERNIE 第一次登顶 GLUE。

2019年12月,文心 ERNIE 就在 GLUE 首次突破90分大关,甚至超越人类3个百分点,创下榜单新纪录。
此后2020年,文心 ERNIE 又在语言生成、跨模态理解、多语言理解等方向取得突破,先后提出了 ERNIE-GEN、ERNIE-VIL、ERNIE-M 等模型,取得10余项 SOTA,登顶各方向权威评测的榜首。比如在全球规模最大的语义评测比赛 SemEval 2020中,文心 ERNIE 就一口气斩获5项世界冠军。ERNIE 2.0 论文被 Paper Digest 团队评为国际人工智能顶级学术会议 AAAI 2020最具影响力的学术论文。文心 ERNIE 还获得2020年度中国人工智能学会优秀科技成果、2020世界人工智能大会最高荣誉 SAIL(Super AI Leader)大奖等。
那么,取得如此多骄人的战绩,文心 ERNIE 又有何独家锻造秘方?

文心 ERNIE 因何登顶 NLP 兵器谱?
文心 ERNIE 基于预训练-微调架构,开创性地将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的新知识,实现模型效果不断进化,如同人类持续学习一样。
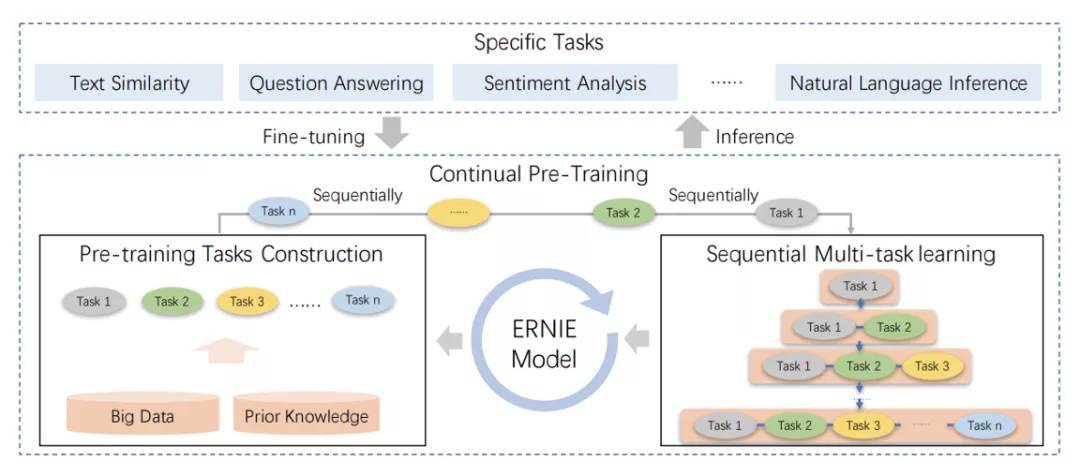
如今登顶 GLUE 榜首的是 ERNIE 二代目,它的预训练过程分为两个步骤: 构建无监督预训练任务学习不同维度的知识; 通过多任务学习实现不同任务的持续训练。
在这个过程中,不同的任务会被有序地加入 ERNIE,通过持续多任务学习,使得模型在学习新任务时不会遗忘此前学到的知识。
而对于不同的特定应用任务,文心 ERNIE 2.0 会使用具体的任务数据微调。
说到此次二代目能在激烈竞争中夺魁的核心秘技,则是层次化学习。
这是一种新的学习范式,其中包含了2个学习层次,分别对应“内功”和“外功”。
内功(内层学习)主要是围绕词法、结构、语义3个方面知识构建的预训练任务。
这也是文心 ERNIE 首次登顶 GLUE 时就已采用的核心技术。
这里也不妨简单举例说明一下。
在词法层面,以知识掩码任务为例。
文心 ERNIE 1.0 模型通过对海量数据中的词、实体等先验语义知识的掩码,学习完整概念的语义表示。相较于 BERT 学习原始语言信号,ERNIE 直接对先验语义知识单元进行建模,增强了模型的语义表示能力。到了文心 ERNIE 2.0,则使用其作为一个预训练任务。

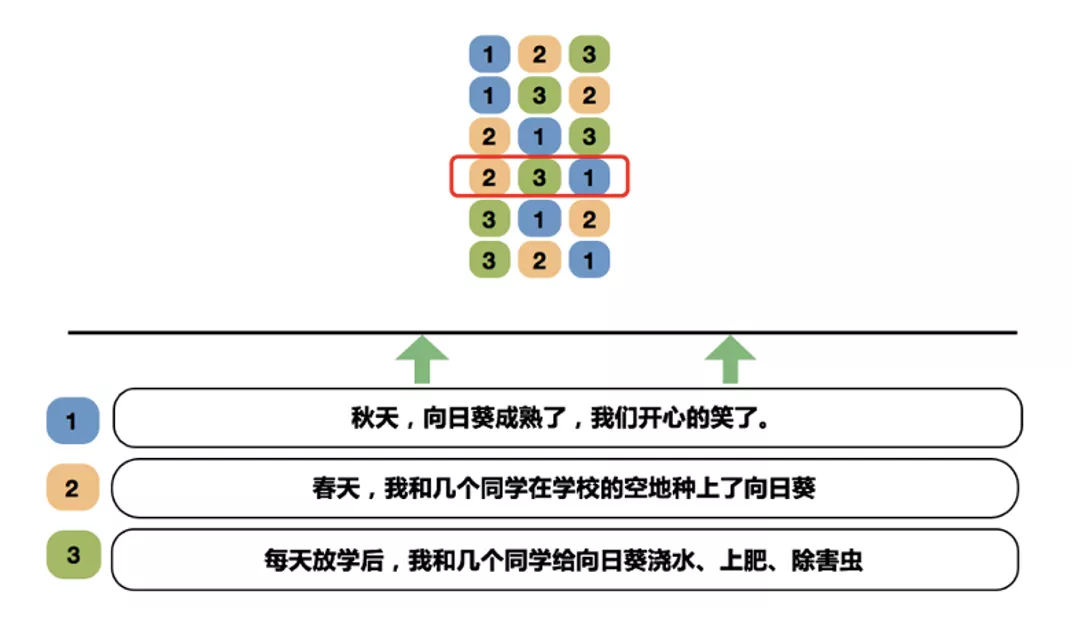
在结构层面,句子排序任务就是其中之一。
句子之间的顺序反映了它们之间的逻辑顺序以及时间顺序。文心 ERNIE 2.0 构建了句子排序预训练任务:在训练过程中,随机将一个段落中的 N 个句子打乱,让模型在 N! 的类别中预测正确的顺序。通过该技术使模型学习了文章结构中所蕴含的丰富知识。
在语义层面,以其中的逻辑关系预测任务为例:
要想对语义信息进行更加精细化的建模,短句之间连词表达出的逻辑关系是关键。因此,文心 ERNIE 2.0 使用短句间的连词构造无监督的关系分类任务,学习句子之间细粒度的逻辑语义知识。
如下图所示:
内功之外,再说外功。外功(外层学习)是模型结构与规模的精细化阶段性学习:
从第一阶段采取循环共享参数 Transformer 结构,到第二阶段进行逐层结构展开,到最后完全展开成非共享结构。
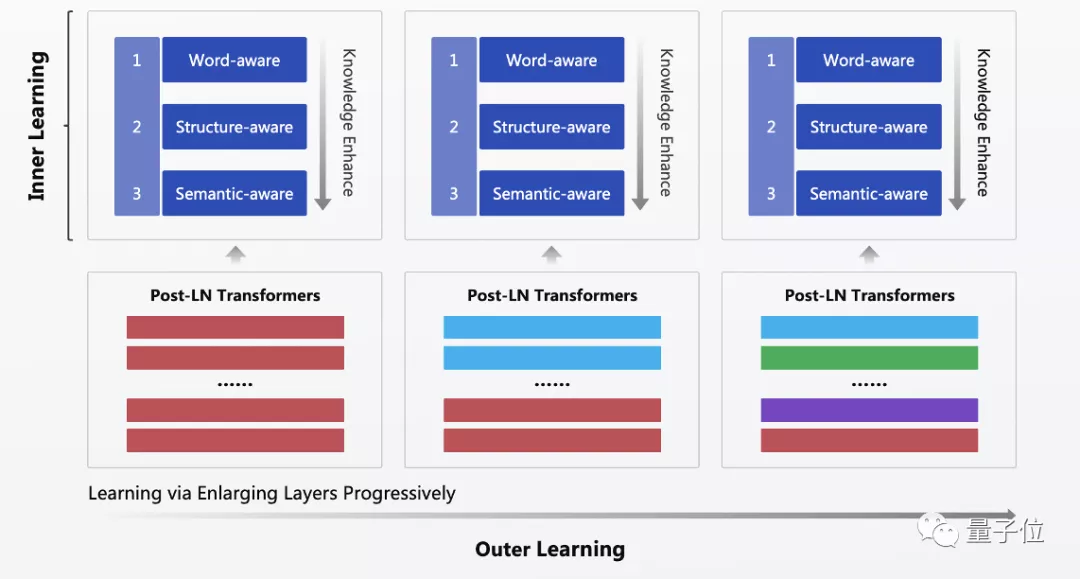
如此带来的训练收益,包括以下几个方面:
首先,平滑的模型参数展开训练方法,解决了大规模 Post-LN(层归一化后置,即 Layer Norm 在 Residual 之后)收敛不稳定的问题。
其次,通过不断展开模型的参数,模型的神经元参数规模逐步增加,文心 ERNIE 能够顺利地吸收规模越来越大的知识输入,进而提升模型学习能力的上限。
与此同时,文心 ERNIE 神经元在扩大的过程中,引入了百度飞桨自研的 Hybrid Sharding 分布式训练算法。
该算法通过在单位通信单元中平均分配网络参数和梯度数据,巧妙避开了网络开销瓶颈,能充分利用硬件优势进行同步通信。
这也使得百亿参数规模的模型训练成为可能,训练时间大幅降低。
这把神兵,你也能用
说了这么多,各位看官想来已等得心焦,迫不及待想问那个关键问题:
能不能直接体验效果?
那!是!当!然!

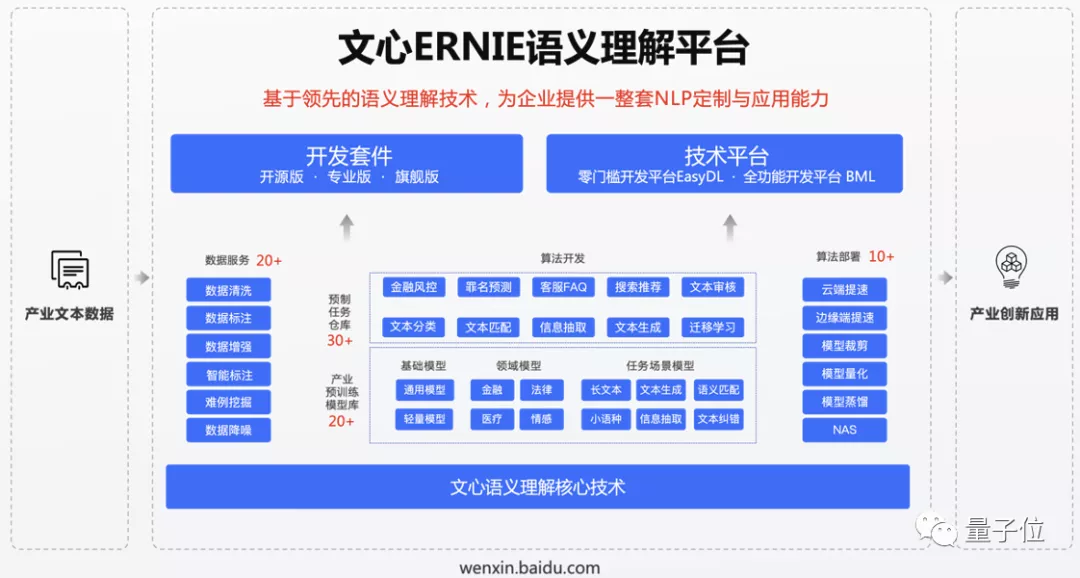
好消息是,百度已经发布了文心 ERNIE 语义理解平台。
该平台集文心 ERNIE 预训练模型集、全面的 NLP 算法集、端到端开发套件和平台服务于一体,提供一站式 NLP 开发与服务,帮助开发者更简单、高效地定制 NLP 模型。
近日,平台重点推出了文心 ERNIE NLP 开发套件专业版和旗舰版。
在专业版中,就预置了大家期盼已久的文心 ERNIE 2.0 预训练模型,面向专业的学术和产业开发需求提供语义理解能力。
旗舰版则面向工业级应用场景,提供最全面的预训练模型库和算法集,并支持金融、媒体等场景化应用。
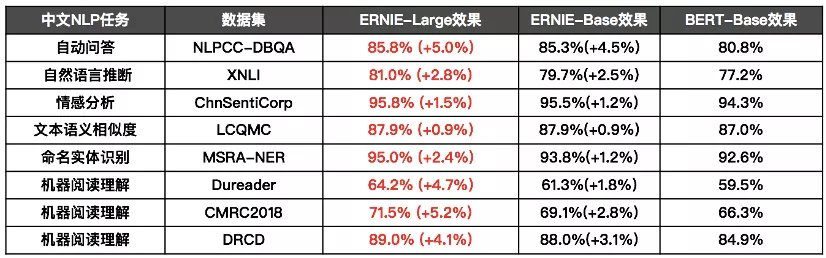
根据实验结果,在机器阅读理解、命名实体识别、自然语言推断、语义相似度、情感分析和问答等9项任务上,文心 ERNIE 2.0 性能均大幅超过 BERT。
同时,专业版开发套件还配套了多种 NLP 经典算法网络,支持文本分类、短文本匹配、序列标注和阅读理解等典型文本处理任务。
基本上,从数据预处理到模型训练,再到模型的预测均可一站体验。
想要试试的话,直接戳进文末文心 ERNIE 官网,申请下载即可。
说起来,两度登顶 GLUE,刷榜各大榜单,在国产预训练“兵器”里,文心 ERNIE 还是第一个。
不过,纵观 GLUE 榜单,就会发现以 ERNIE 为首,越来越多 made in China 的神兵利器,都在不断突破,书写自己的篇章。
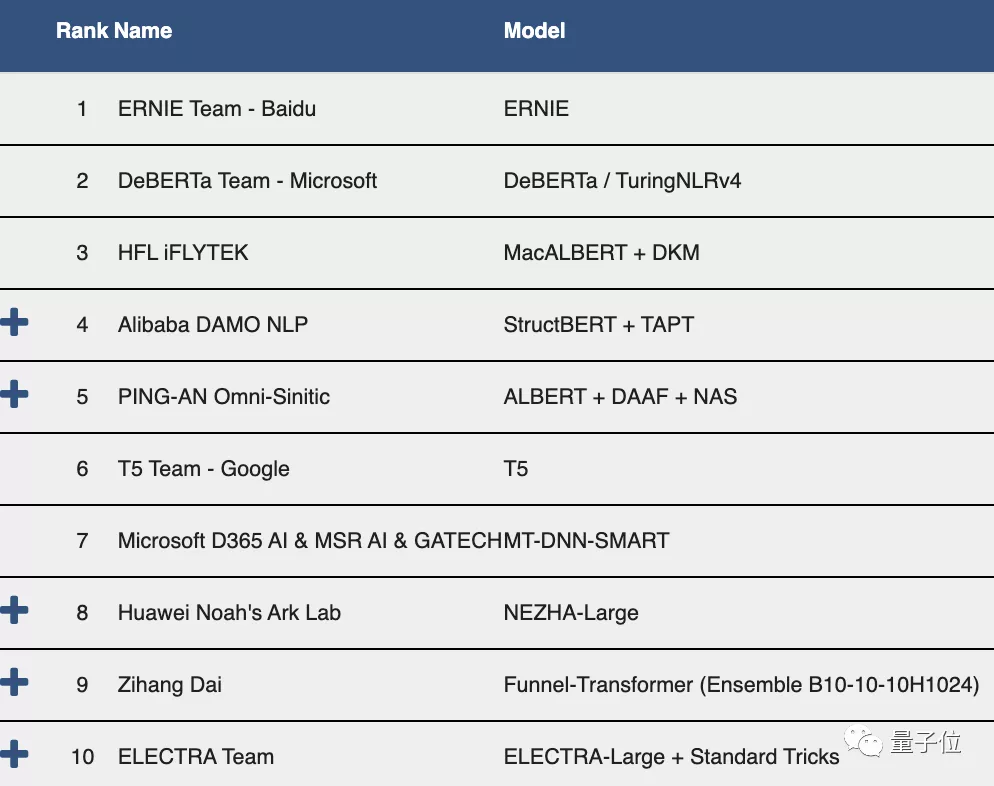
也正是在开放共享的氛围之中,中国的 NLP 力量已悄然发展、壮大,走向了世界舞台中央。
那么,要来体验一下吗?
文心ERNIE官网: https://wenxin.baidu.com/wenxin/sdk
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢