
【论文标题】Grounding Physical Concepts of Objects and Events Through Dynamic Visual Reasoning 【论文链接】https://arxiv.org/abs/2103.16564 【作者团队】Zhenfang Chen, Jiayuan Mao, Jiajun Wu, Kwan-Yee Kenneth Wong, Joshua B. Tenenbaum,Chuang Gan 【发表时间】2021.3.30 【推荐理由】论文收录于ICLR-2021,研究人员提出一个统一的框架——动态概念学习者,它能将对象和事件的物理概念从视频和语言中建立起来。经过训练,动态概念学习者框架可以跨帧检测和关联物体、视觉属性和物理事件,理解事件之间的因果关系,进行未来和反事实预测,并利用这些提取的呈现方式来回答查询。
论文研究的是原始视频的动态视觉推理问题,这是一个具有挑战性的问题。目前,最先进的模型通常需要从模拟中对物理对象的属性和事件进行密集的监督,这在现实生活中是不切实际的。动态概念学习者框架首先采用轨迹提取器来跟踪每个对象的时间,并将其表示为一个潜在的、以对象为中心的特征向量。在这种以对象为中心的表示方式的基础上,动态概念学习者框架学习使用图网络来逼近对象之间的动态交互;同时,动态概念学习者框架加入了一个语义解析器,将问题解析成语义程序;最后,加入了一个程序执行器,利用学习到的动态模型,运行程序来回答问题。动态概念学习者框架在CLEVRER上实现了最先进的性能,这是一个具有挑战性的因果视频推理数据集,即使不使用模拟中的地面真实属性和碰撞标签进行训练。研究人员进一步在新提出的由CLEVRER衍生的视频检索和事件定位数据集上测试动态概念学习者框架,显示出其强大的泛化能力。
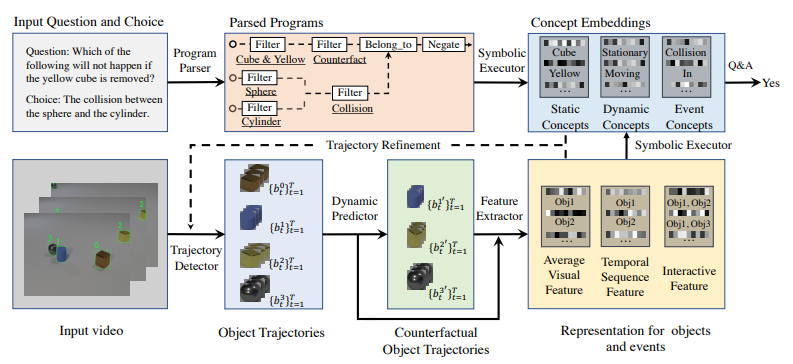
图:用于推理反事实问题的动态概念学习者框架的体系结构
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢