
论文标题:A Video Is Worth Three Views: Trigeminal Transformers for Video-based Person Re-identification 论文链接:https://arxiv.org/abs/2104.01745 作者单位:大连理工大学(卢湖川团队) & 中科智云
TMT:基于Transformer的视频行人Re-ID新网络(三叉戟结构),表现SOTA!性能优于GRL(CVPR 2021)、TCLNet等网络,代码即将开源!
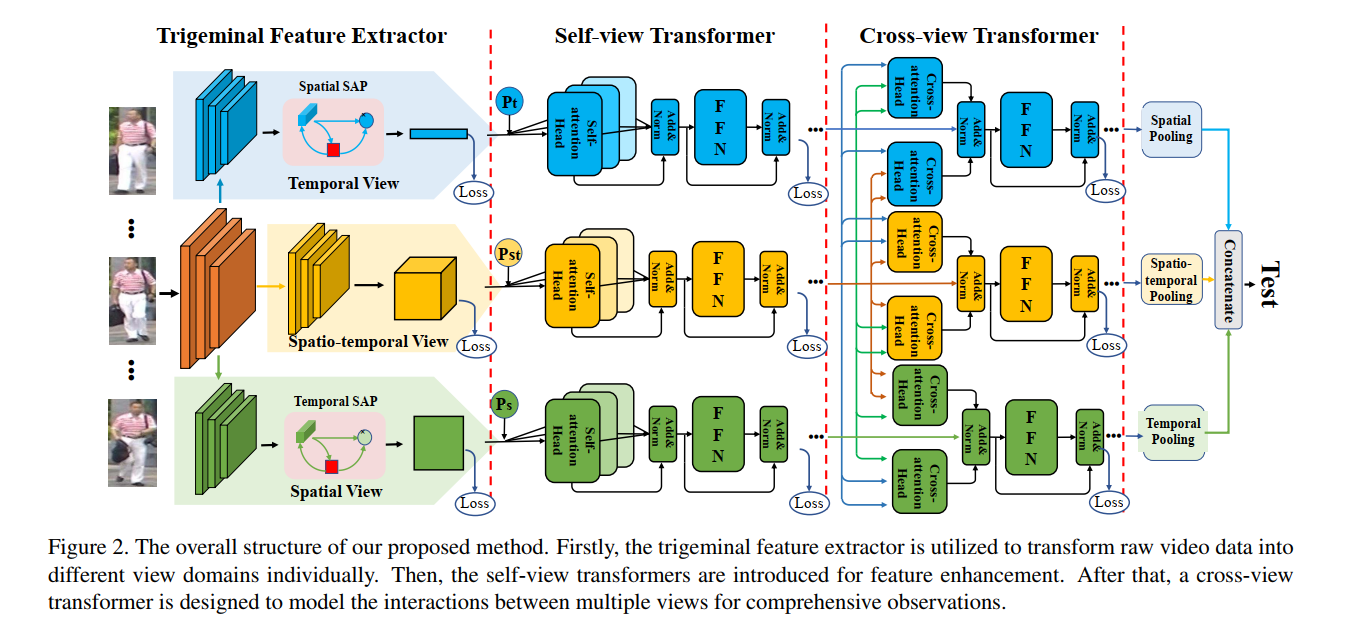
基于视频的行人重识别(Re-ID)旨在在不重叠的摄像头下检索同一个人的视频序列。先前的方法通常集中于有限的视图,例如空间,时间或时空视图,这些视图缺乏在不同特征域中的观察结果。为了捕获更丰富的感知并提取更全面的视频表示,在本文中,我们为基于视频的人Re-ID提出了一个名为Trigeminal Transformers(TMT)的新颖框架。更具体地说,我们设计了一个三叉特征提取器,将原始视频数据共同转换为空间,时间和时空域。此外,在视觉Transformer取得巨大成功的启发下,我们介绍了基于视频行人Re-ID的Transformer结构。在我们的工作中,提出了三个自视Transformer,以利用局部特征之间的关系来增强空间,时间和时空域中的信息。此外,提出了跨视图转换器以聚合多视图特征,以实现全面的视频表示。实验结果表明,与其他基于公共Re-ID基准的最新方法相比,我们的方法可以实现更好的性能。我们将发布用于模型复制的代码。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢