
【论文标题】Compressing Visual-linguistic Model via Knowledge Distillation 【作者团队】Zhiyuan Fang, Jianfeng Wang,Xiaowei Hu,Lijuan Wang,Yezhou Yang,Zicheng Liu 【发表时间】2021/04/05 【机构】亚利桑那州立大学、微软 【论文链接】https://arxiv.org/pdf/2104.02096.pdf 【推荐理由】 本文出自亚利桑那州立大学和微软联合团队,作者以目标检测器的 proposal 作为迁移学习的中间表征,设计了能够对齐学生网络和教师网络隐藏表征和注意力分布的视觉-语言跨模态知识蒸馏框架,在图像描述和视觉问答问题上取得了出色的效果。
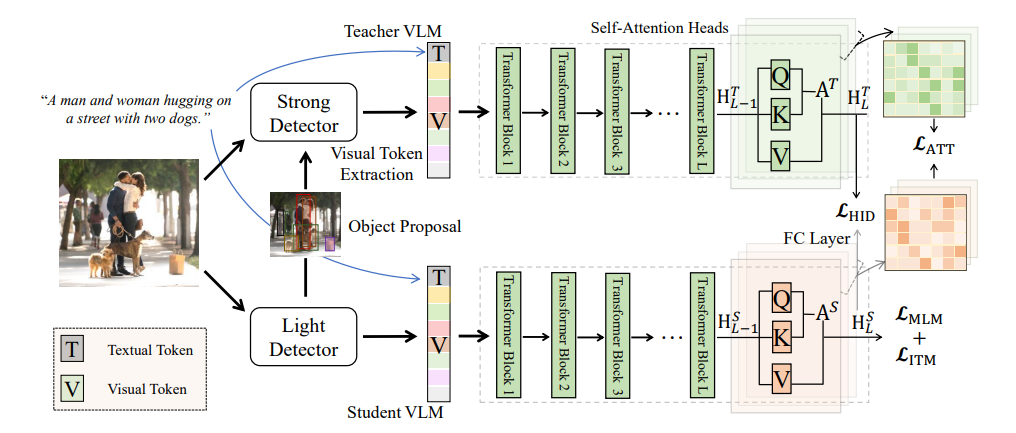
近年来,尽管研究人员在「视觉-语言」(VL)表征的预训练任务上取得了激动人心的进展,但是鲜有工作涉及小型 VL 模型。在本文中,作者研究通过知识蒸馏技术有效地将基于 Transformer 的大型 VL 模型压缩为一个小型 VL 模型。该研究中主要的挑战在于从教师网络和学生网络的不同的检测其中提取到的区域视觉词例不一致,导致隐藏表征和注意力分布无法对齐。 为了解决这一问题,作者采用与学生检测器提出的区域相同的 proposal 对教师进行再训练,其中再训练使用的特征来自教师网络自己的目标检测器。通过对齐的网络输入,适配后的教师网络能够通过中间表征迁移知识。 具体而言,我们使用均方误差损失来模拟 Transformer 模块内的注意力分布,并通过与存储在样本队列中的负表征进行对比,提出了一个词例级别的噪声对比损失来对齐隐藏状态。实验结果表明,本文提出的蒸馏方法可以显著提高小型 VL 模型在图像描述和视觉问答任务上的性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢