
【论文标题】SiT: Self-supervised vIsion Transformer 【作者团队】Sara Atito, Muhammad Awais, Josef Kittler 【发表时间】2021/04/08 【机构】萨里大学 【论文链接】https://arxiv.org/pdf/2104.03602.pdf 【代码链接】https://github.com/Sara-Ahmed/SiT
【推荐理由】 本文出自英国萨里大学,作者将自监督学习和视觉 Transformer 相结合,考虑了基于多种前置任务的自监督视觉训练机制,提出了一种自监督视觉 Transformer,该框架性能大大超过了现有的自监督学习方法。
近年来,自监督学习方法在计算机视觉领域域监督学习的性能差距越来越小,因此引起了广泛的关注。在自然语言处理领域中,自监督学习和 Transformer 模型的组合已经是一种经典搭配。最近的一些文献表明,Transformer 模型在计算机视觉领域也越来越流行。到目前为止,视觉 Transformer 在大规模有监督数据或某些协同监督数据(例如,教师网络)上取得了很好的效果。这些有监督预训练视觉 Transformer 在具有较小改变的下游任务中取得了非常好的效果。
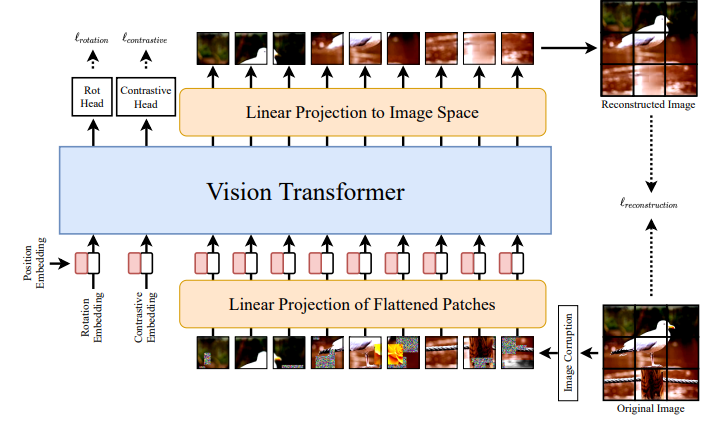
在本文中,作者研究了用于预训练视觉 Transformer 的自监督学习方法的优点,并且将它们用于下游的分类任务。作者提出了一种自监督视觉 Transformer(SiT),并且讨论了一些得到辅助模型自监督训练机制。SiT 架构的灵活性使我们可以将其用作一种自编码器,并且被用于多种自监督任务。
通过实验,作者表明我们可以对预训练的 SiT 进行调优,并将其用于小规模数据集上的下游任务。实验结果证明了 SiT的有效性和自监督学习的可行性,其性能大大超过了已有的自监督学习方法。此外,SiT 非常适用于少样本学习,我们可以通过直接利用从 SiT 中学习到的特征训练线性分类器,从而学习实用的表征。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢