
论文标题:Monocular 3D Multi-Person Pose Estimation by Integrating Top-Down and Bottom-Up Networks 论文链接:https://arxiv.org/abs/2104.01797 代码链接:https://github.com/3dpose/3D-Multi-Person-Pose 作者单位:新加坡国立大学 & 腾讯游戏AI中心
表现SOTA!性能优于VIBE、SPIN等网络,代码即将开源!
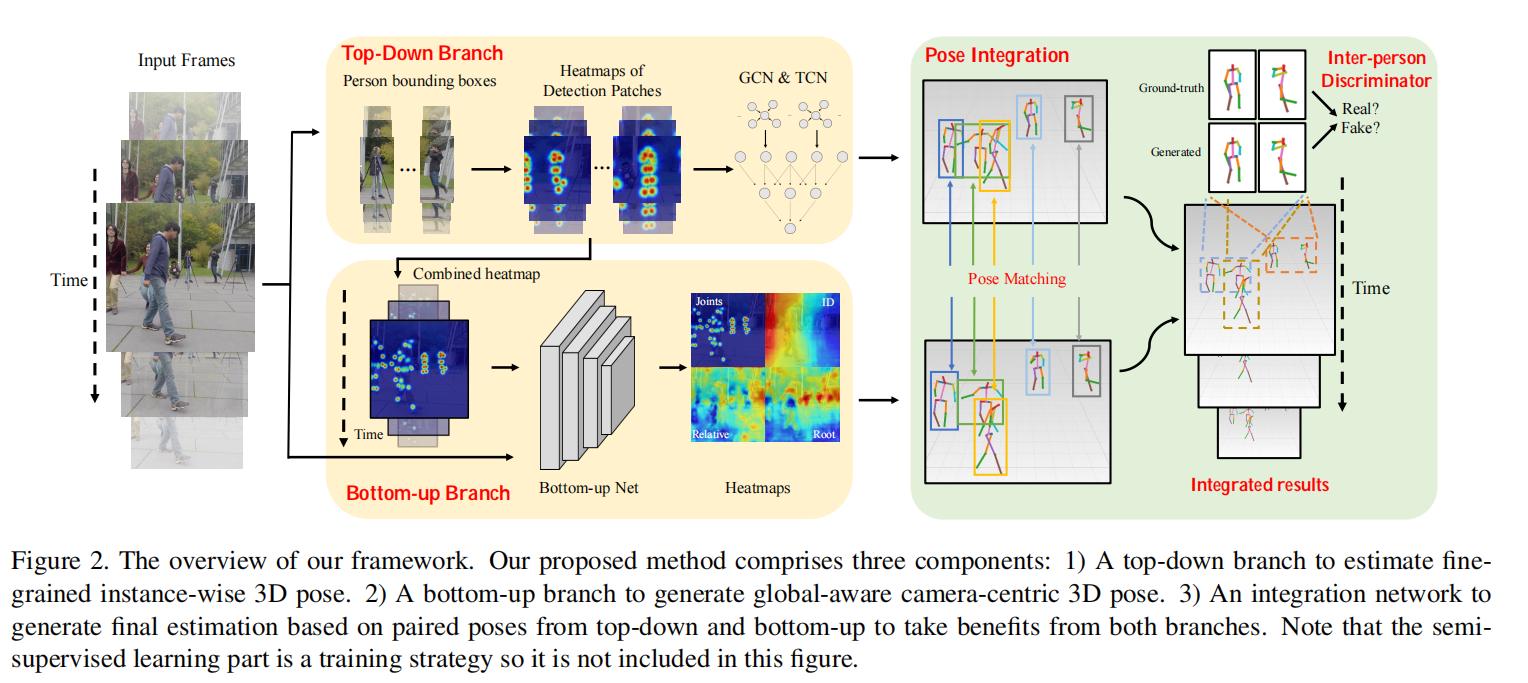
在单目视频3D多人姿态估计中,人与人之间的遮挡和紧密互动会导致人类检测错误,并且人类关节分组不可靠。现有的自上而下的方法依靠人工检测,因此遭受这些问题的困扰。现有的自下而上的方法不使用人工检测,而是以相同的比例同时处理所有人员,从而使他们对多人比例变化敏感。为了应对这些挑战,我们提出将自上而下和自下而上的方法相结合,以发挥其优势。我们的自上而下的网络会估计所有人的人体关节,而不是图像patches中的人为关节,从而使它对于可能出现的错误边界框具有鲁棒性。我们的自下而上的网络结合了基于人类检测的归一化热图,使该网络在处理规模变化时更加强大。最后,将自上而下和自下而上的网络的估计3D姿势输入到我们的集成网络中,以获取最终3D姿势。除了自上而下和自下而上的网络的集成之外,与现有的仅针对单人设计的姿态识别器不同,因此无法评估自然的人际互动,我们提出了一种两人式姿势识别器,用于强制自然的两人互动。最后,我们还应用了一种半监督方法来克服3D真实数据的稀缺性。与最先进的基准相比,我们的定量和定性评估显示了我们方法的有效性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢