
【标题】Learning to Reweight Imaginary Transitions for Model-Based Reinforcement Learning 【论文链接】https://arxiv.org/pdf/2104.04174.pdf 【作者团队】Wenzhen Huang, Qiyue Yin, Junge Zhang, Kaiqi Huang 【发表时间】2021.4.9 【推荐理由】本文提出了一种新颖且有效的基于模型的强化学习方法,该方法通过训练权重函数来自适应地调整所有已生成过渡的权重,以减少它们的潜在负面影响。实验结果表明,该方法在多个复杂的连续控制任务上与现有方法相比具有最优的性能。
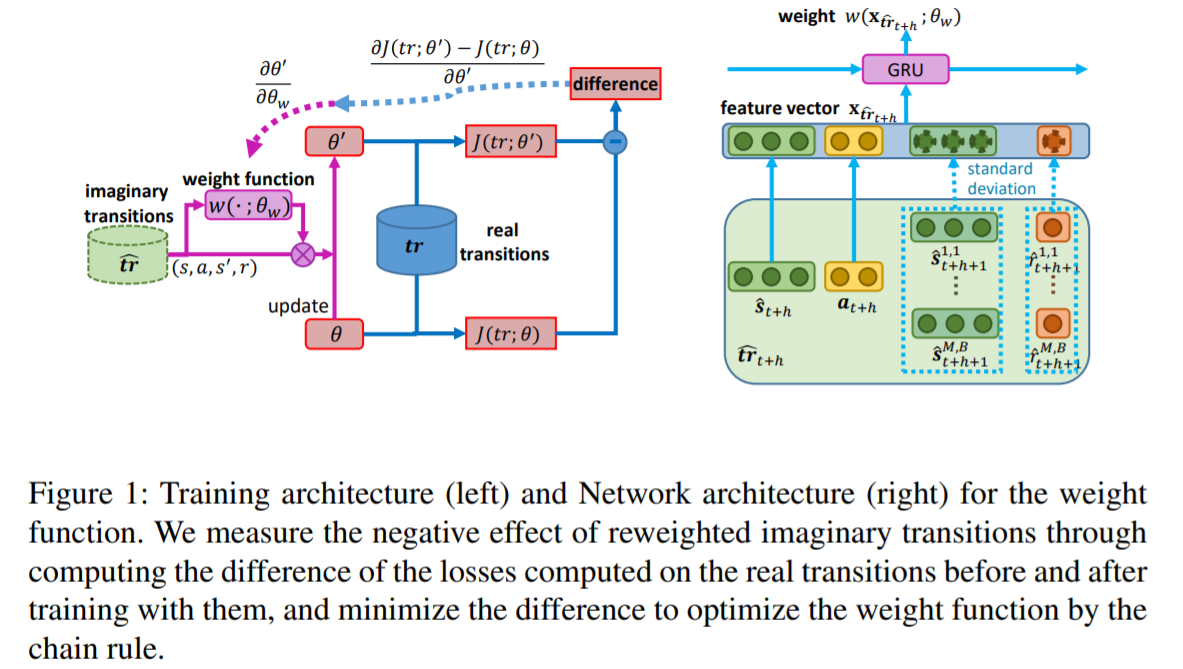
基于模型的强化学习(RL)通过使用由学习的动力学模型生成的假想轨迹,比无模型的强化学习具有更高的样本效率。当模型不准确或有偏差时,假想的轨迹可能不利于训练动作的价值和策略功能。为了缓解这一问题,本文提出自适应地对虚拟进行加权,以减少不良生成轨迹的负面影响。更具体地说,当我们使用过渡来训练行动价值和策略函数时,通过计算对真实样本计算的损失的变化来评估虚拟过渡的效果。基于此评价标准,本文构造了一种通过精心设计的元梯度算法来对每个虚拟过渡进行加权的想法。大量的实验结果表明,在多种任务上,该方法优于基于模型和无模型的RL算法。可视化不断变化的权重进一步降低了使用权重方案的必要性。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢