
【论文标题】MSA Transformer 【作者团队】Roshan Rao, Jason Liu, Robert Verkuil, Joshua Meier, John F. Canny, Pieter Abbeel, Tom Sercu, Alexander Rives 【发表时间】2021/02/13 【机 构】FAIR,美国 【论文链接】https://www.biorxiv.org/content/10.1101/2021.02.12.430858v1.full 【推荐理由】使用MSA进行蛋白预训练,达到了目前蛋白预训练模型的最优效果
在数百万不同序列上训练的无监督蛋白质语言模型可以学习蛋白质的结构和功能。迄今为止研究的蛋白质语言模型已经可以做到从序列训练进行推理,而计算生物学中长期以来的方法是通过对每个家族独立拟合一个模型,从进化相关的家族序列中进行推断。本文将这两种范式结合起来,引入了一个以MSA(多重序列比对)的形式将一组序列作为输入的蛋白质语言模型。该模型在输入序列上交错进行行列attention,在许多蛋白质家族中使用MLM(掩码语言模型)的变体进行训练。该模型的性能远远超过了当前最先进的无监督结构学习方法,参数效率远高于之前最先进的蛋白质语言模型。
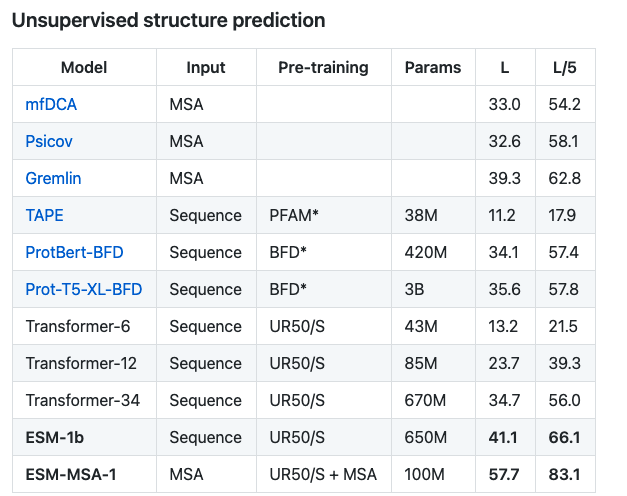 非监督蛋白contact预测的结果比较,本文对MSA transformer在结构预测任务,无监督contact预测,以及监督contact预测和二级结构预测上的表现进行了结果分析,使用了MSA的ESM模型在2600万通过使用HHblits采样生成平均深度为1192的MSA的数据集上进行1亿参数训练,大幅领先其他模型。在同源序列少的时候,MSA模型和其他模型的差异更明显。
非监督蛋白contact预测的结果比较,本文对MSA transformer在结构预测任务,无监督contact预测,以及监督contact预测和二级结构预测上的表现进行了结果分析,使用了MSA的ESM模型在2600万通过使用HHblits采样生成平均深度为1192的MSA的数据集上进行1亿参数训练,大幅领先其他模型。在同源序列少的时候,MSA模型和其他模型的差异更明显。
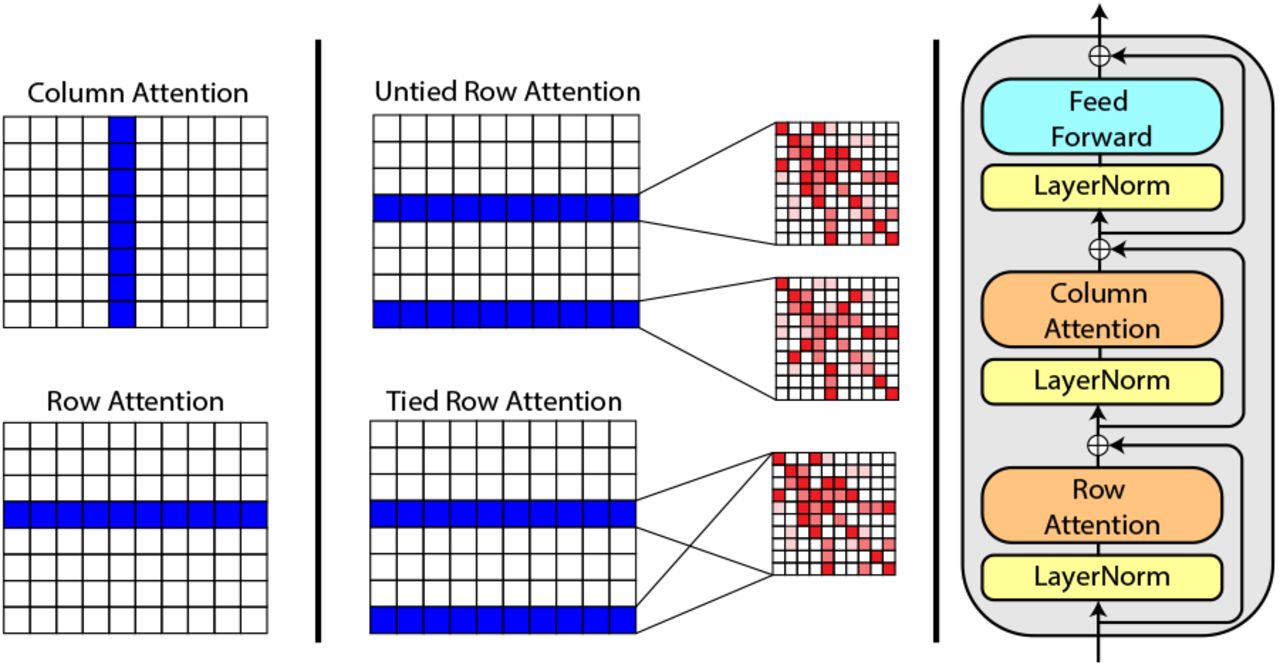 MSA transformer使用了稀疏注意力,通过行列注意力降低计算成本。本文同时对MLM loss针对MSA进行了适配,比较了在MSA上均匀随机地mask token与mask掉MSA的整列,并最终在前者上得到了最好的模型。需要注意的是,被mask的token不仅可以从上下文氨基酸的不同位置预测,也可从同一位置的相关序列获得信息。
MSA transformer使用了稀疏注意力,通过行列注意力降低计算成本。本文同时对MLM loss针对MSA进行了适配,比较了在MSA上均匀随机地mask token与mask掉MSA的整列,并最终在前者上得到了最好的模型。需要注意的是,被mask的token不仅可以从上下文氨基酸的不同位置预测,也可从同一位置的相关序列获得信息。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢