
【论文标题】Protein sequence design with deep generative models 【作者团队】Zachary Wu, Kadina E. Johnston, Frances H. Arnold, Kevin K. Yang 【发表时间】2021/04/09 【机 构】加州理工,美国 【论文链接】https://arxiv.org/pdf/2104.04457v1.pdf 【推荐理由】来自诺奖得主的深度学习蛋白设计综述
蛋白质工程旨在识别具有更优性质的蛋白质序列。在机器学习的指导下,蛋白序列生成方法可以借鉴先验知识和实验工作来改进这一过程。本文讨论了深度生成模型在蛋白工程中的三种应用,(1)将学习到的蛋白序列表征和预训练模型用于下游学习任务,这是对已建立的蛋白质工程框架的重要改进;(2)使用生成模型生成蛋白质序列;(3)通过调整生成模型进行定向优化,使生成的蛋白质序列在某性质上的概率提升。这些方法将与实验验证生成序列的研究相结合。
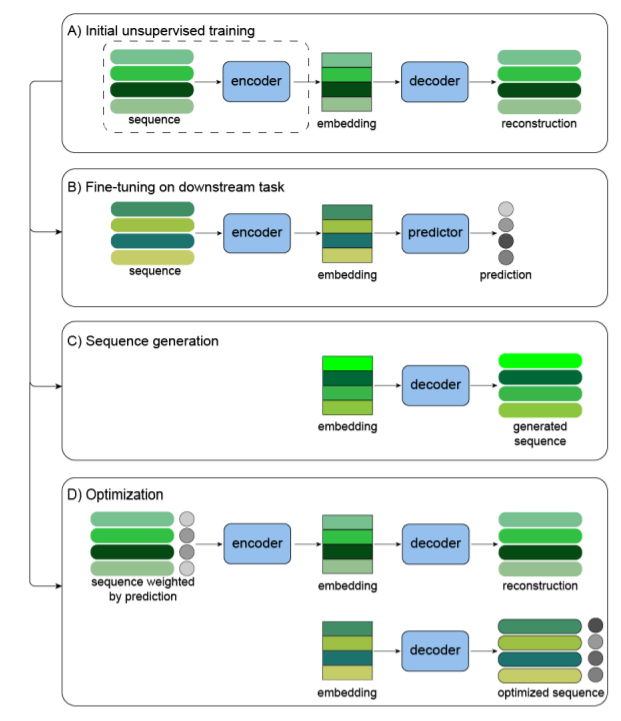 - 在A部分无监督学习期间,生成式解码器通过embedding学习生成与无监督训练集类似的蛋白质,学习的表征有可能比序列或氨基酸物理化学特性的编码更有信息量,它们将离散的蛋白质序列编码在一个连续和压缩的隐空间中。
- 然后,这些embedding可以在B部分,微调部分,被用作下游建模任务的输入。理想的情况是,他们能够捕获上下文信息并简化了下游建模。这其中较有代表性的应用为eUnirep。
- 解码器可用于在C部分生成新的功能序列,作者在文中对蛋白序列的常见深度生成模型进行了概述,包括VAE,GAN和自回归模型等。
- 最后,在D部分进行优化,从而使得整个生成模型可以生成针对特定属性的功能性序列。途径包括:对输入GAN的数据进行偏向,代表论文为抗体Wasserstein GANs, FBGAN,CbAS等;以及强化学习,代表论文 DyNA-PPO等。虽然在用生成模型优化蛋白质序列方面已经出现了大量的工作,但这一方向仍处于起步阶段,尚不清楚哪种方法或框架具有普遍的优势。
- 在A部分无监督学习期间,生成式解码器通过embedding学习生成与无监督训练集类似的蛋白质,学习的表征有可能比序列或氨基酸物理化学特性的编码更有信息量,它们将离散的蛋白质序列编码在一个连续和压缩的隐空间中。
- 然后,这些embedding可以在B部分,微调部分,被用作下游建模任务的输入。理想的情况是,他们能够捕获上下文信息并简化了下游建模。这其中较有代表性的应用为eUnirep。
- 解码器可用于在C部分生成新的功能序列,作者在文中对蛋白序列的常见深度生成模型进行了概述,包括VAE,GAN和自回归模型等。
- 最后,在D部分进行优化,从而使得整个生成模型可以生成针对特定属性的功能性序列。途径包括:对输入GAN的数据进行偏向,代表论文为抗体Wasserstein GANs, FBGAN,CbAS等;以及强化学习,代表论文 DyNA-PPO等。虽然在用生成模型优化蛋白质序列方面已经出现了大量的工作,但这一方向仍处于起步阶段,尚不清楚哪种方法或框架具有普遍的优势。
作者最后表示,通过将机器学习与多轮的实验相结合,数据驱动的蛋白质工程有望从昂贵的实验室工作中获得极大的收益,使蛋白工程师们能够快速地设计出有用的序列!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢