
【论文标题】M-Evolve: Structural-Mapping-Based Data Augmentation for Graph Classification 【作者团队】Jiajun Zhou, Jie Shen, Shanqing Yu, Guanrong Chen, Qi Xuan 【发表时间】2021/04/03 【机 构】浙江大学,中国 & 香港城市大学,中国 【论文链接】https://arxiv.org/pdf/2007.05700v4.pdf 【推荐理由】图数据增强
图分类旨在识别图形的类别标签,在药物分类、毒性检测、蛋白质分析等方面发挥着重要作用。然而,由于基准数据集的规模限制,图分类模型很容易陷入过度拟合和泛化不足。为了改善这种情况,本文引入了对图的数据增强(即图增强),并提出了四种方法:随机映射、顶点相似度映射、motif-随机映射和motif-相似度映射。通过对图结构的启发式转换,为小规模的基准数据集生成更多的弱标签数据。此外,作者提出了一个通用的模型进化框架,命名为M-Evolve,该框架结合预训练,图增强、数据过滤和模型重训练来优化预训练的图分类器。在6个基准数据集上的实验表明,M-Evolve框架可以帮助现有的图分类模型在小规模基准数据集上缓解训练中的过度拟合和泛化问题,成功地使平均精度提高了3 - 13%。
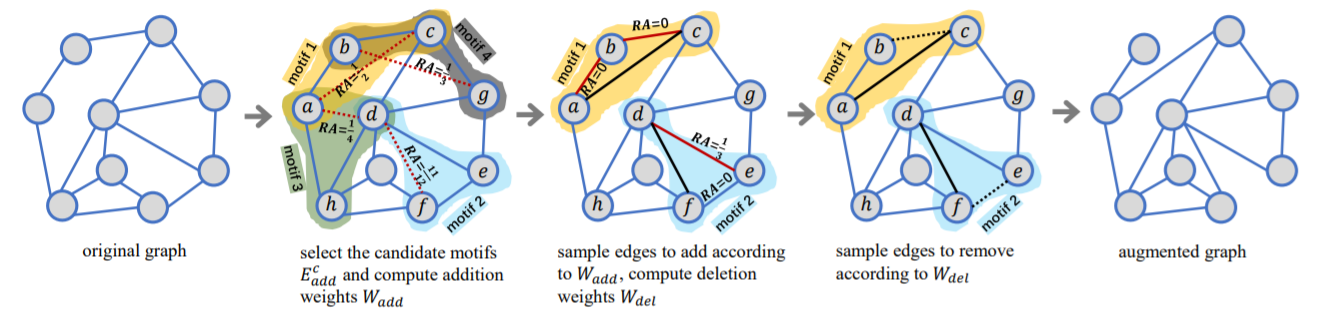 上图展示了motif相似性映射,本文展示的4种图增强方法分别为:
1. 随机映射,即随机移除一些边并连接相同数量的顶点;
2. 顶点相似度映射,在随机映射的基础上加权;
3. motif-随机映射,边的随机交换发生在motif内部;
4. motif-相似度映射,如上图展示,源自motif-随机映射并在边采样策略引入了顶点相似度,结合了方法2和方法3。
上图展示了motif相似性映射,本文展示的4种图增强方法分别为:
1. 随机映射,即随机移除一些边并连接相同数量的顶点;
2. 顶点相似度映射,在随机映射的基础上加权;
3. motif-随机映射,边的随机交换发生在motif内部;
4. motif-相似度映射,如上图展示,源自motif-随机映射并在边采样策略引入了顶点相似度,结合了方法2和方法3。
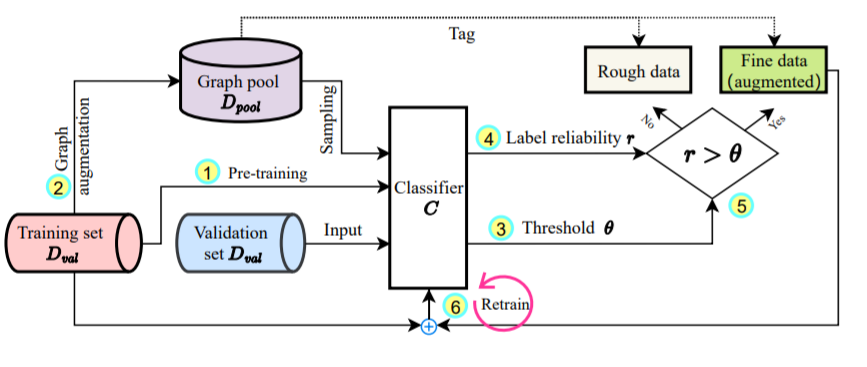 M-Evolve的架构。完整的工作流程分为以下步骤:
1. 利用训练集对图分类器进行预训练;
2. 应用图增强生成图数据池;
3. 利用验证集计算标签可靠性阈值;
4. 计算从图数据池中采样的样本的标签可靠性;
5. 过滤数据,利用阈值得到增强集;
6. 利用训练集和增强集的联合重新训练图分类器。
M-Evolve的架构。完整的工作流程分为以下步骤:
1. 利用训练集对图分类器进行预训练;
2. 应用图增强生成图数据池;
3. 利用验证集计算标签可靠性阈值;
4. 计算从图数据池中采样的样本的标签可靠性;
5. 过滤数据,利用阈值得到增强集;
6. 利用训练集和增强集的联合重新训练图分类器。
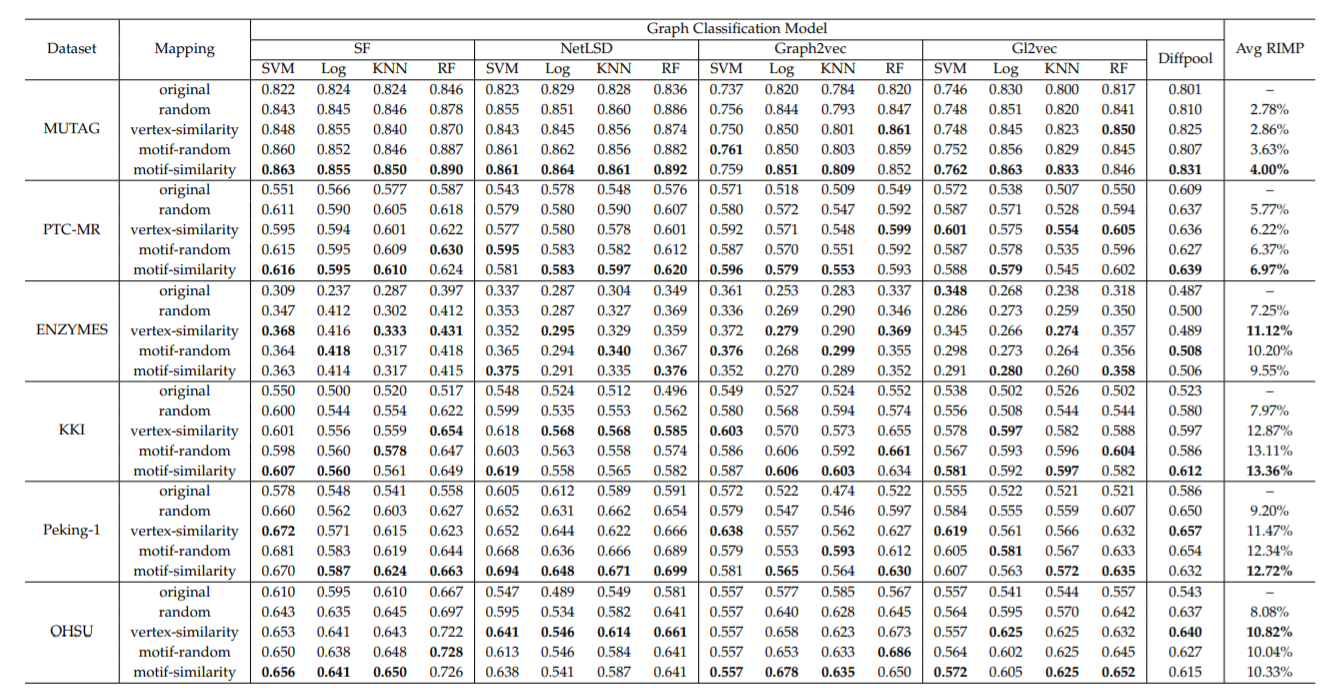 上图显示了在分子图/蛋白图/大脑图等图分类任务上的表现,总的来说,这些M-Evolve框架模型在96.81%情况下都能获得较高的平均分类精度,表现优异。
上图显示了在分子图/蛋白图/大脑图等图分类任务上的表现,总的来说,这些M-Evolve框架模型在96.81%情况下都能获得较高的平均分类精度,表现优异。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢